BeLFusion: Latent Diffusion for Behavior-Driven Human Motion Prediction
ICCV 2023
German Barquero, Sergio Escalera, and Cristina Palmero
University of Barcelona and Computer Vision Center, Spain

Abstract
Stochastic human motion prediction (HMP) has generally been tackled with generative adversarial networks and variational autoencoders. Most prior works aim at predicting highly diverse movements in terms of the skeleton joints’ dispersion. This has led to methods predicting fast and motion-divergent movements, which are often unrealistic and incoherent with past motion. Such methods also neglect contexts that need to anticipate diverse low-range behaviors, or actions, with subtle joint displacements. To address these issues, we present BeLFusion, a model that, for the first time, leverages latent diffusion models in HMP to sample from a latent space where behavior is disentangled from pose and motion. As a result, diversity is encouraged from a behavioral perspective. Thanks to our behavior coupler’s ability to transfer sampled behavior to ongoing motion, BeLFusion’s predictions display a variety of behaviors that are significantly more realistic than the state of the art. To support it, we introduce two metrics, the Area of the Cumulative Motion Distribution, and the Average Pairwise Distance Error, which are correlated to our definition of realism according to a qualitative study with 126 participants. Finally, we prove BeLFusion’s generalization power in a new cross-dataset scenario for stochastic HMP.Motivation

BeLFusion, by building a latent space where behavior is disentangled from poses and motion, detaches diversity from the traditional coordinate-based perspective and promotes it from a behavioral viewpoint.

Figure below shows the evolution of 10 superimposed predictions along time in two actions from H36M (sitting down, and giving directions), and two datasets from AMASS (DanceDB, and GRAB). First, the acceleration of GSPS and DivSamp at the beginning of the prediction leads to extreme poses very fast, abruptly transitioning from the observed motion. Second, it shows the capacity of BeLFusion to adapt the diversity predicted to the context. For example, the diversity of motion predicted while giving directions focuses on the upper body, and does not include holistic extreme poses. Interestingly, when just sitting, the predictions include a wider range of full-body movements like laying down, or bending over. A similar context fitting is observed in the AMASS cross-dataset scenario. For instance, BeLFusion correctly identifies that the diversity must target the upper body in the GRAB dataset, or the arms while doing a dance step.
Architecture

A latent diffusion model conditioned on an encoding \(x=c\) of the observation, \(\mathbf{X}\), progressively denoises a sample from a zero-mean unit variance multivariate normal distribution into a behavior code. Then, the behavior coupler \(\mathcal{B}_{\phi}\) decodes the prediction by transferring the sampled behavior to the target motion, \(\mathbf{x}_{m}\). In our implementation, \(f_{\Phi}\) is a conditional U-Net with cross-attention, and \(h_{\lambda}\), \(g_{\alpha}\), and \(\mathcal{B}_{\phi}\) are one-layer recurrent neural networks.
Implicit diversity loss
Human3.6M

AMASS
Regularization relaxation usually leads to out-of-distribution predictions. This is often solved by employing additional complex techniques like pose priors, or bone-length losses that regularize the other predictions. BeLFusion can dispense with it due to mainly two reasons: 1) Denoising diffusion models are capable of faithfully capturing a greater breadth of the training distribution than GANs or VAEs; 2) The variational training of the behavior coupler makes it more robust to errors in the predicted behavior code.
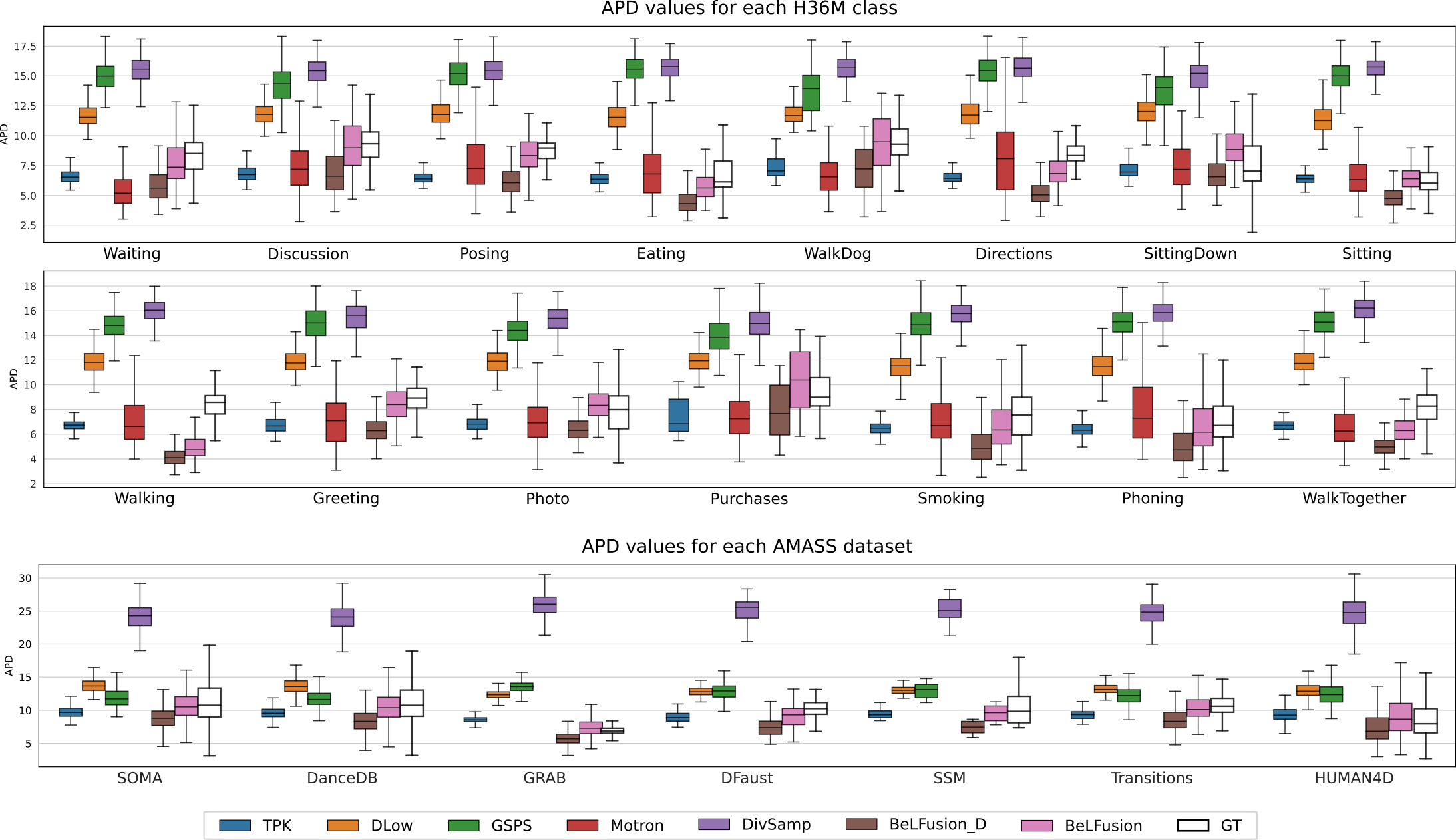
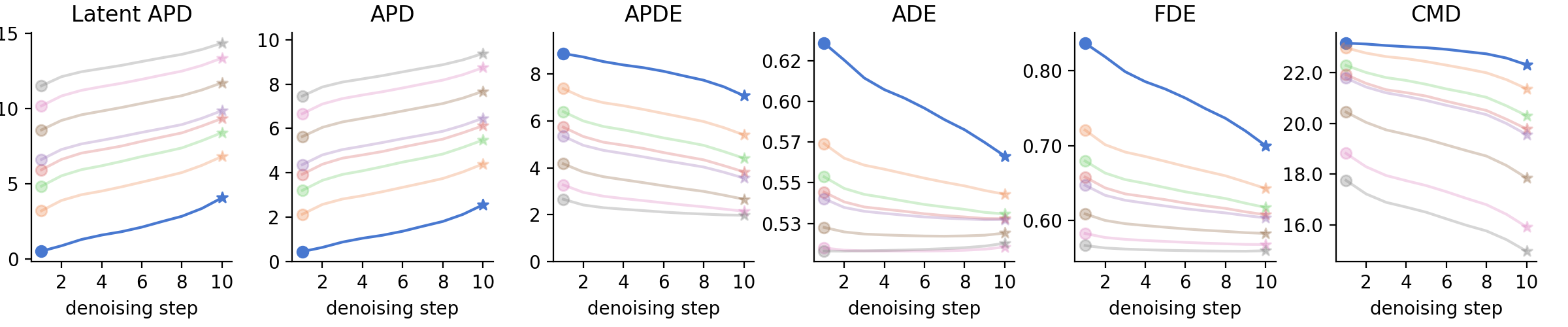
In general, increasing k enhances the samples' diversity, accuracy, and realism. For k < 5, going through the whole chain of denoising steps boosts accuracy. However, for k > 5, further denoising only boosts diversity- and realism-wise metrics (APD, CMD, FID), and makes the fast single-step inference extremely accurate.
Examples in motion
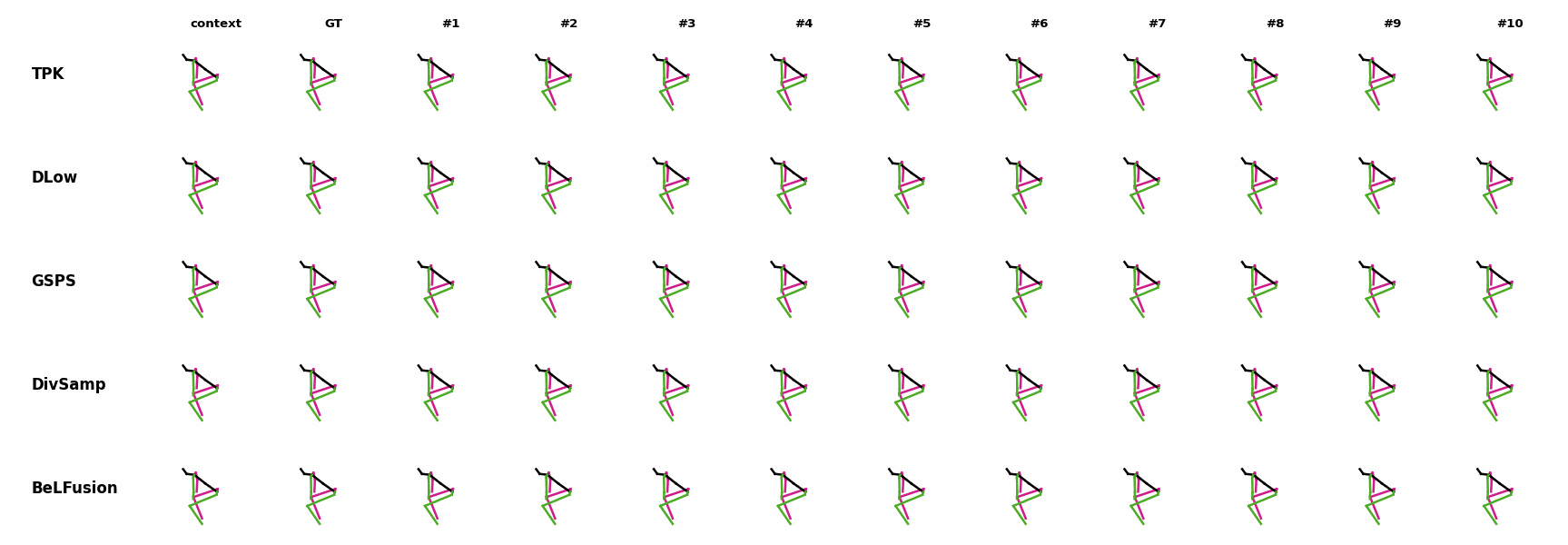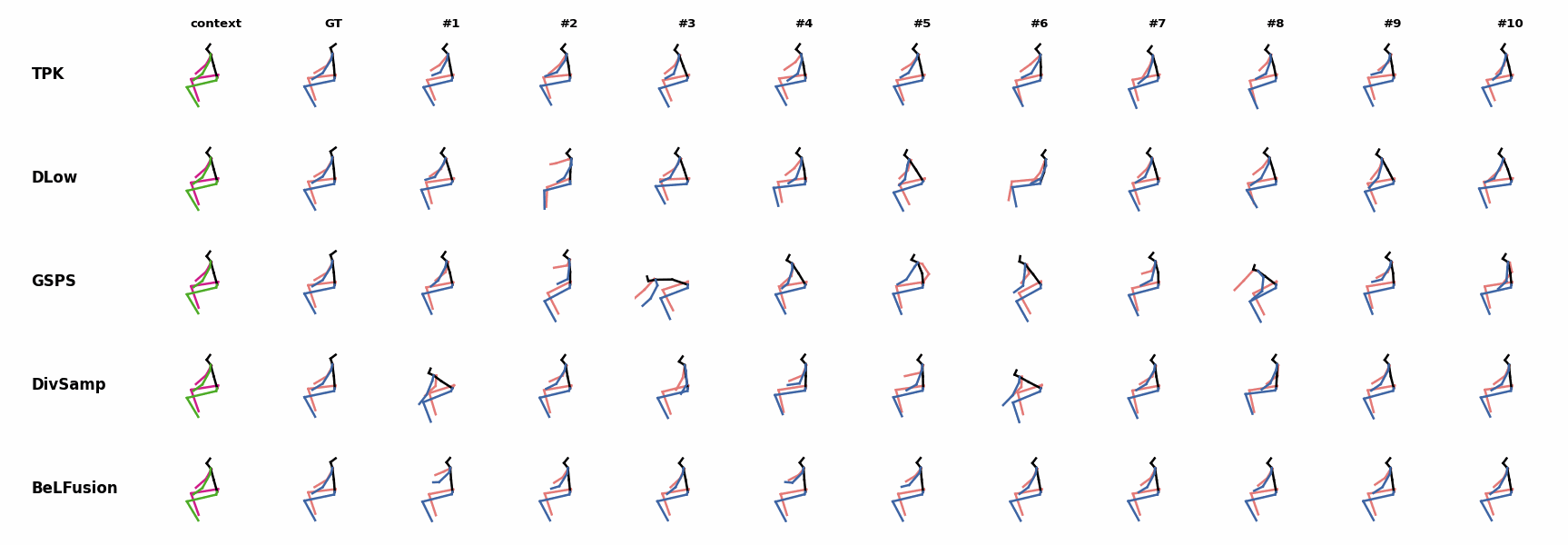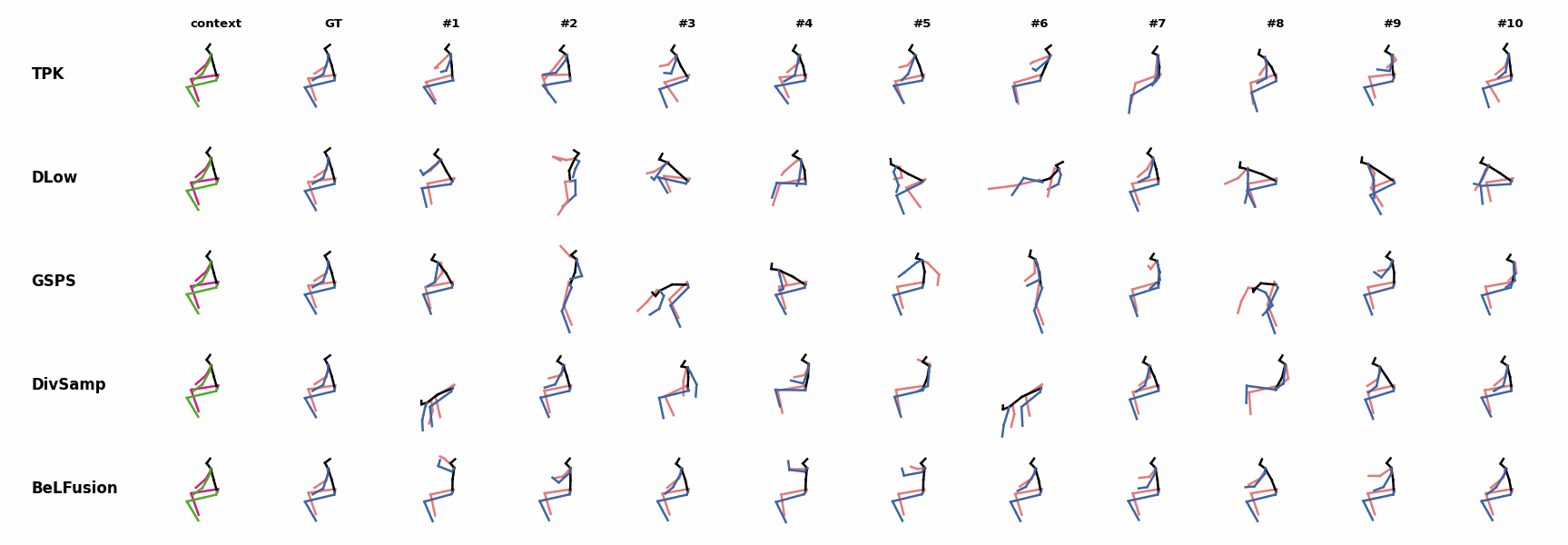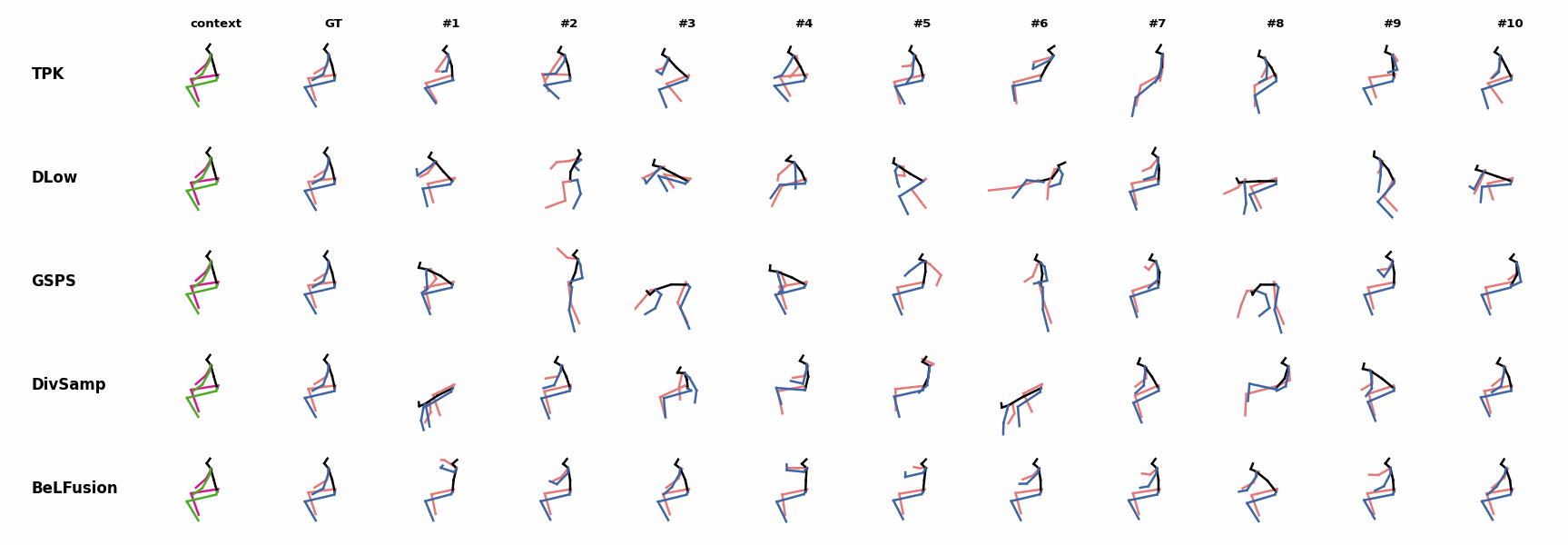 Whereas for ‘H_4_Sitting’ BeLFusion’s predicted motions showcase a high variety of arms-related actions, its predictions for sequences where the arms are used in an ongoing action (‘H_402_Smoking’, ‘H_446_Smoking’, and ‘H_541_Phoning’) have a more limited variety of arms motion.
Whereas for ‘H_4_Sitting’ BeLFusion’s predicted motions showcase a high variety of arms-related actions, its predictions for sequences where the arms are used in an ongoing action (‘H_402_Smoking’, ‘H_446_Smoking’, and ‘H_541_Phoning’) have a more limited variety of arms motion.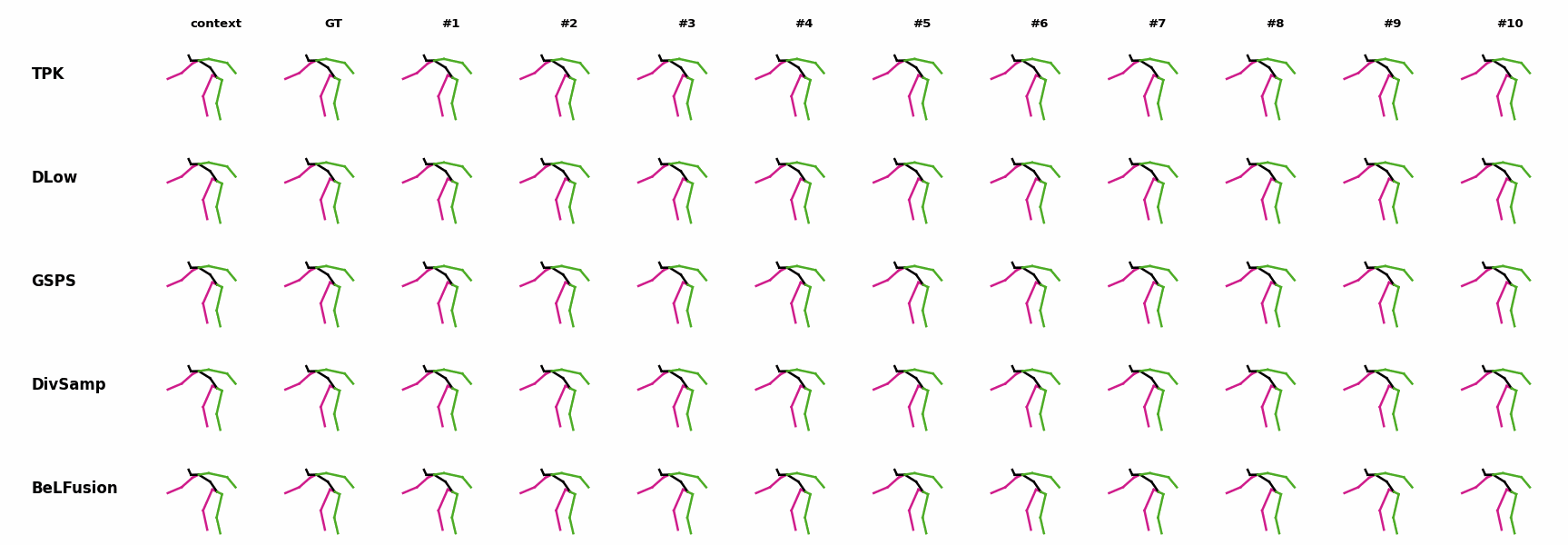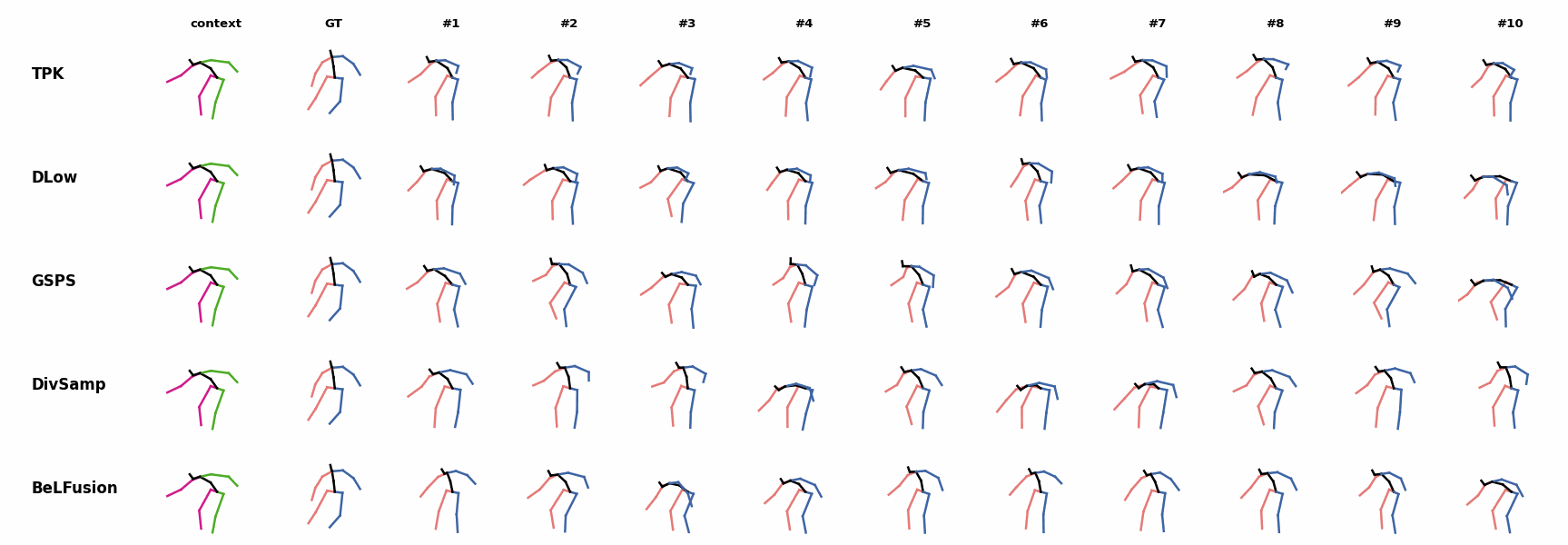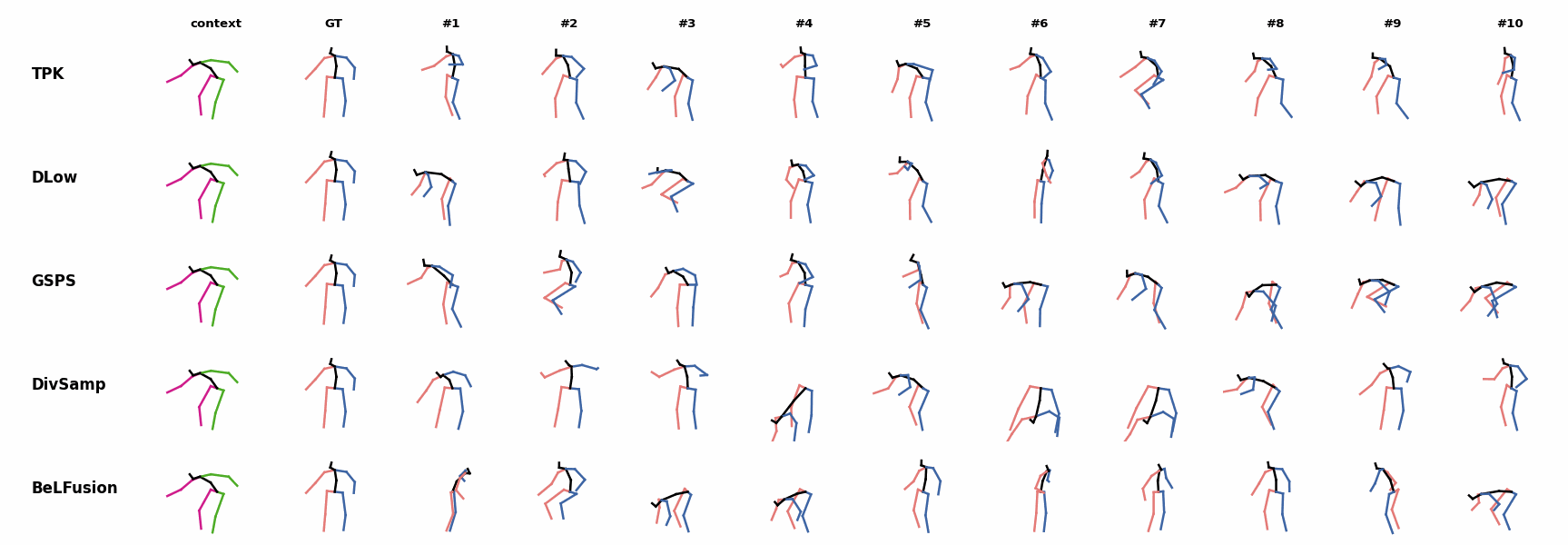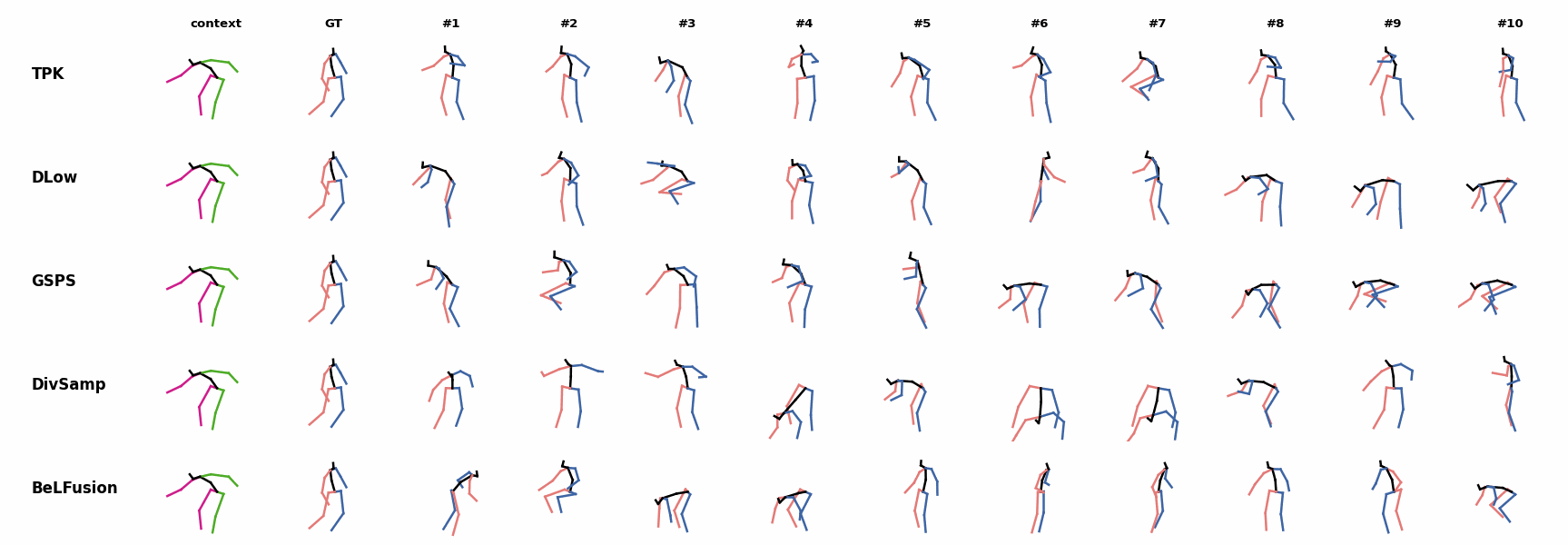 None of the models is able to model the high-speed walking movement from the ground truth.
None of the models is able to model the high-speed walking movement from the ground truth. BeLFusion's predictions for sequences where the arms are used in an ongoing action (‘H_402_Smoking’, ‘H_446_Smoking’, and ‘H_541_Phoning’) have a more limited variety of arms motion.
BeLFusion's predictions for sequences where the arms are used in an ongoing action (‘H_402_Smoking’, ‘H_446_Smoking’, and ‘H_541_Phoning’) have a more limited variety of arms motion.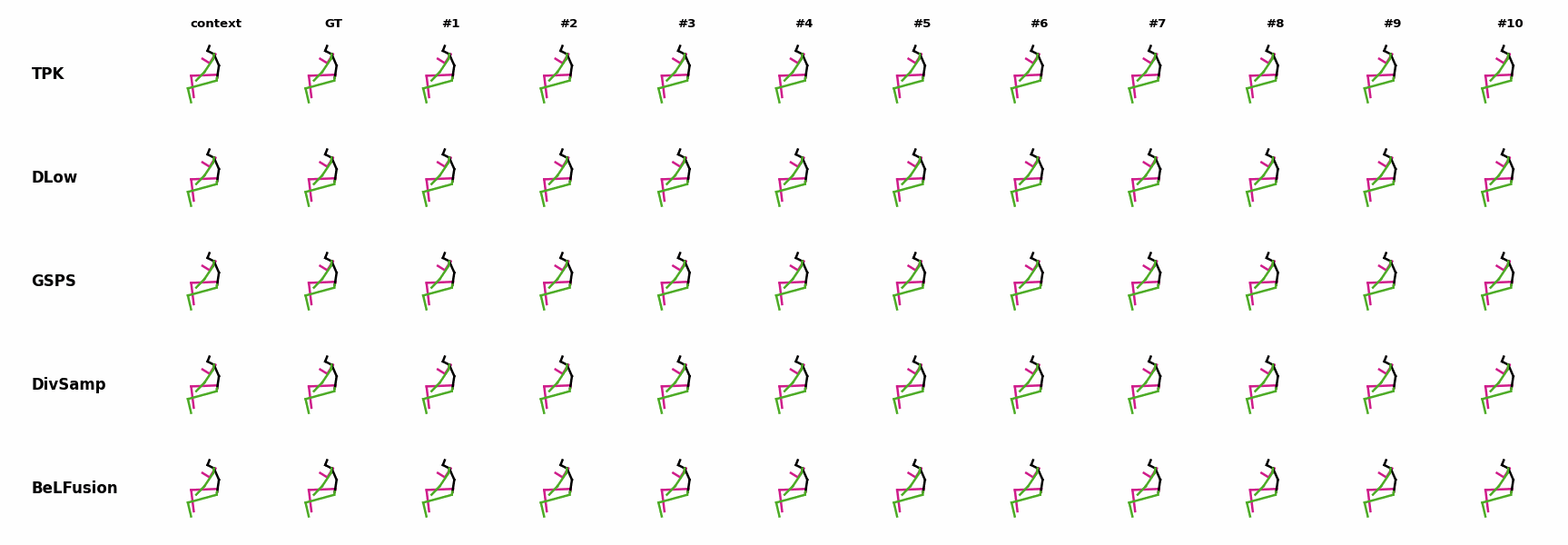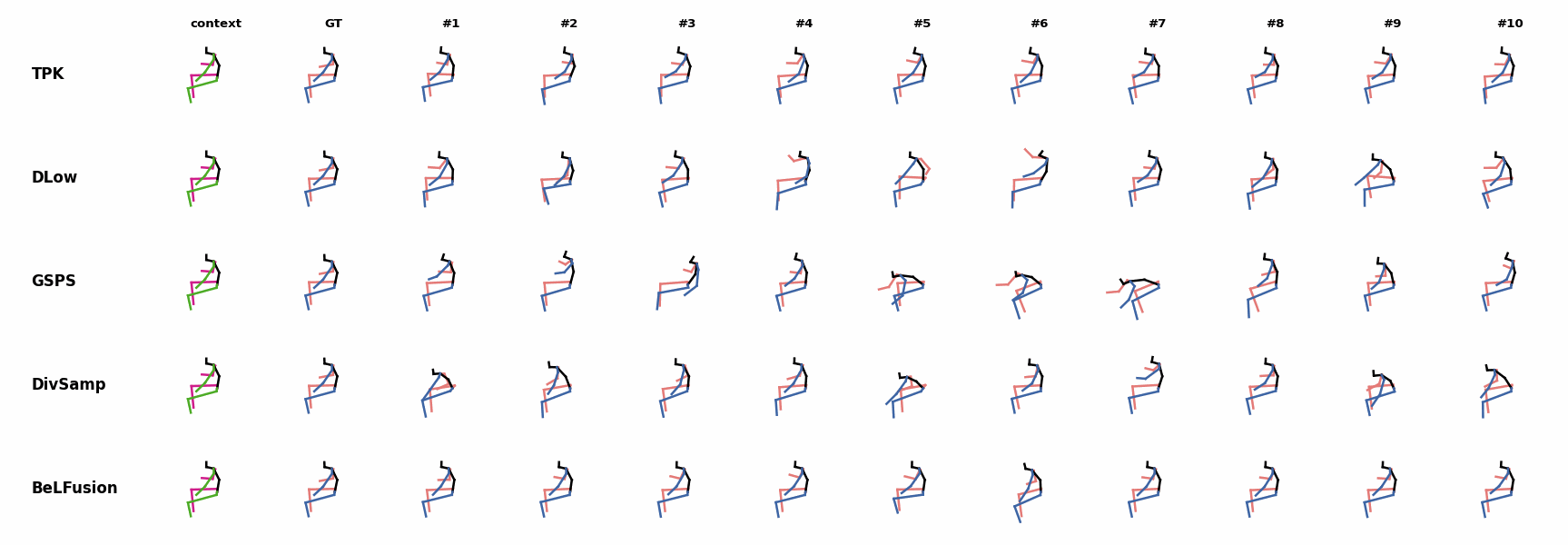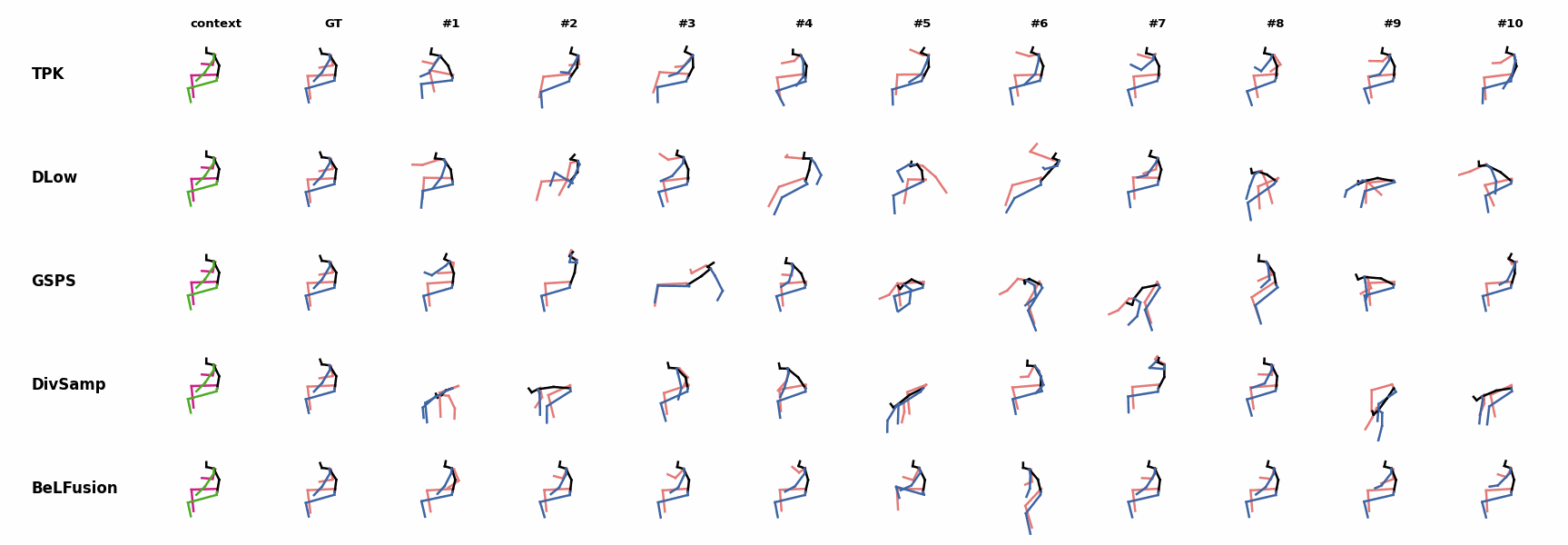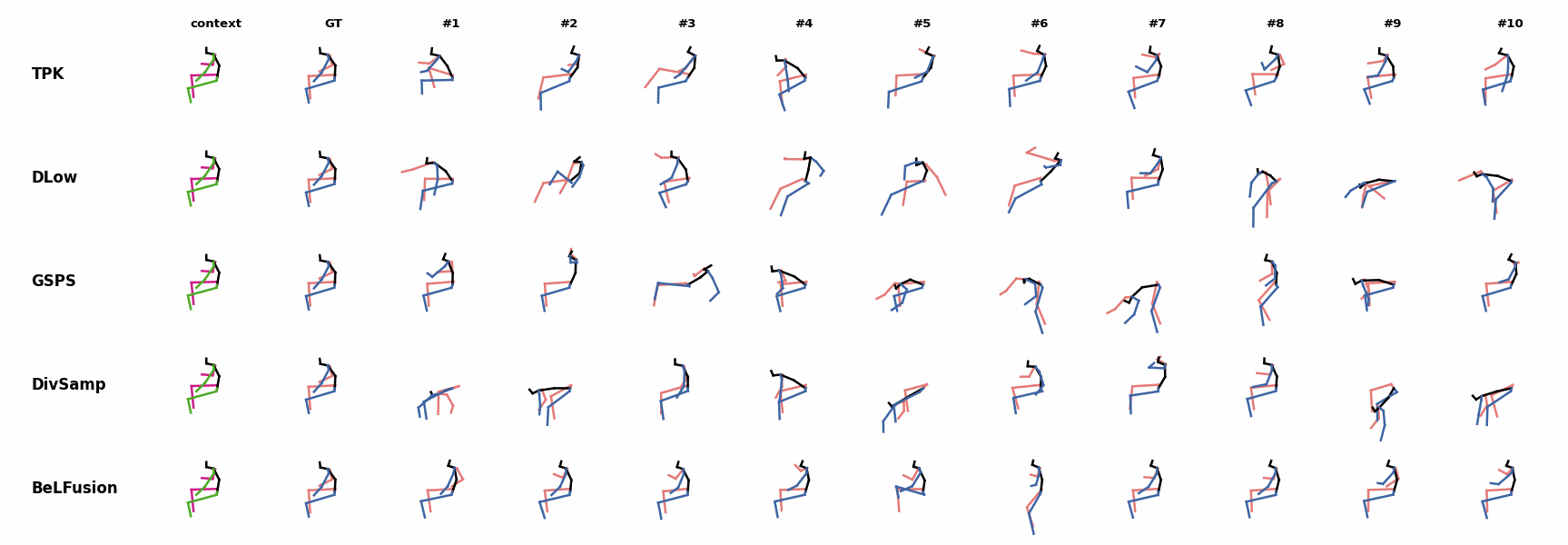 BeLFusion's predictions for sequences where the arms are used in an ongoing action (‘H_402_Smoking’, ‘H_446_Smoking’, and ‘H_541_Phoning’) have a more limited variety of arms motion.
BeLFusion's predictions for sequences where the arms are used in an ongoing action (‘H_402_Smoking’, ‘H_446_Smoking’, and ‘H_541_Phoning’) have a more limited variety of arms motion.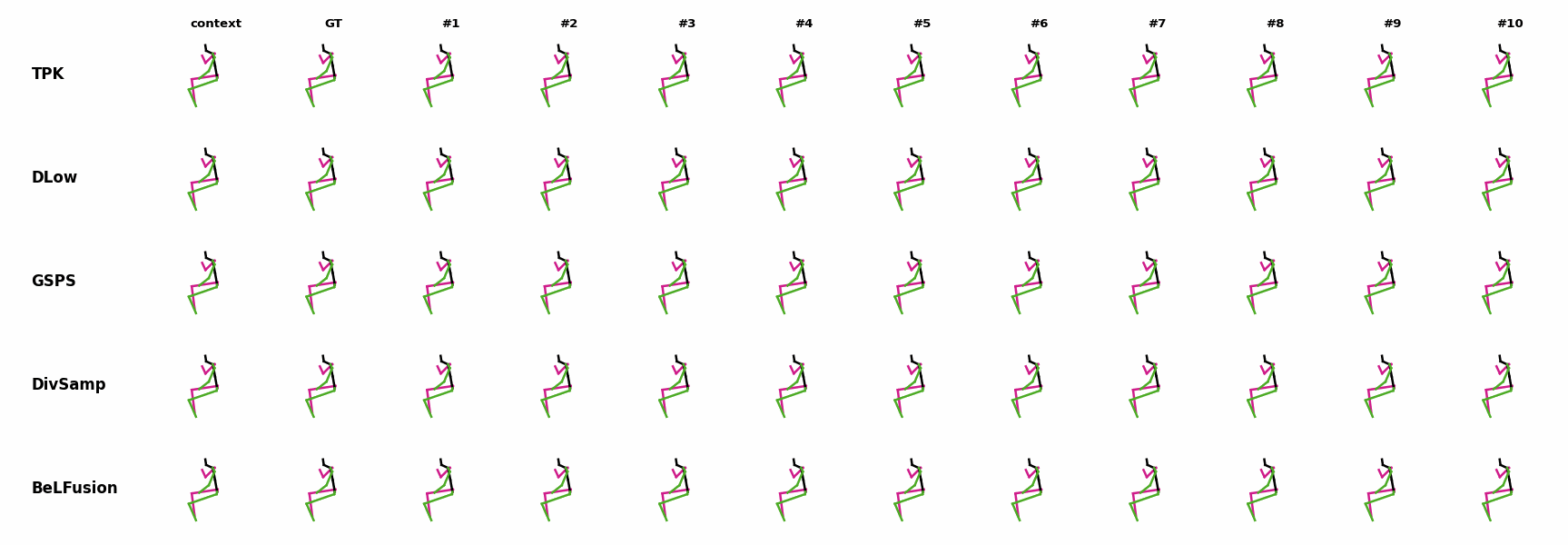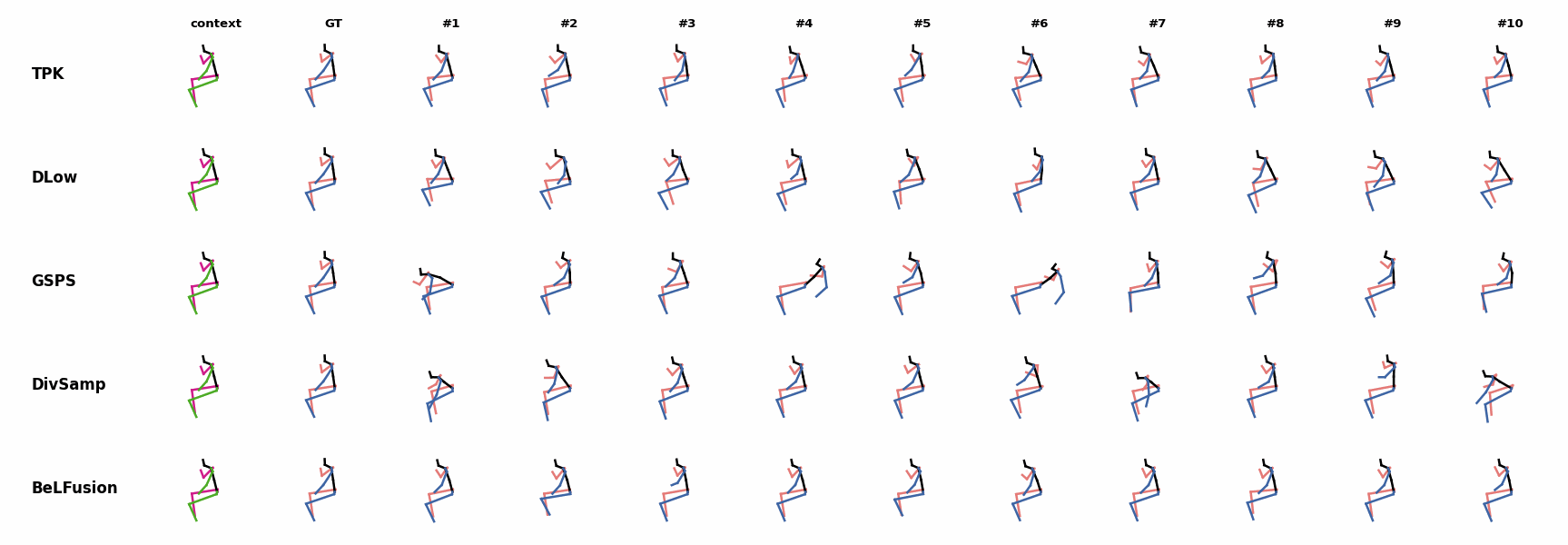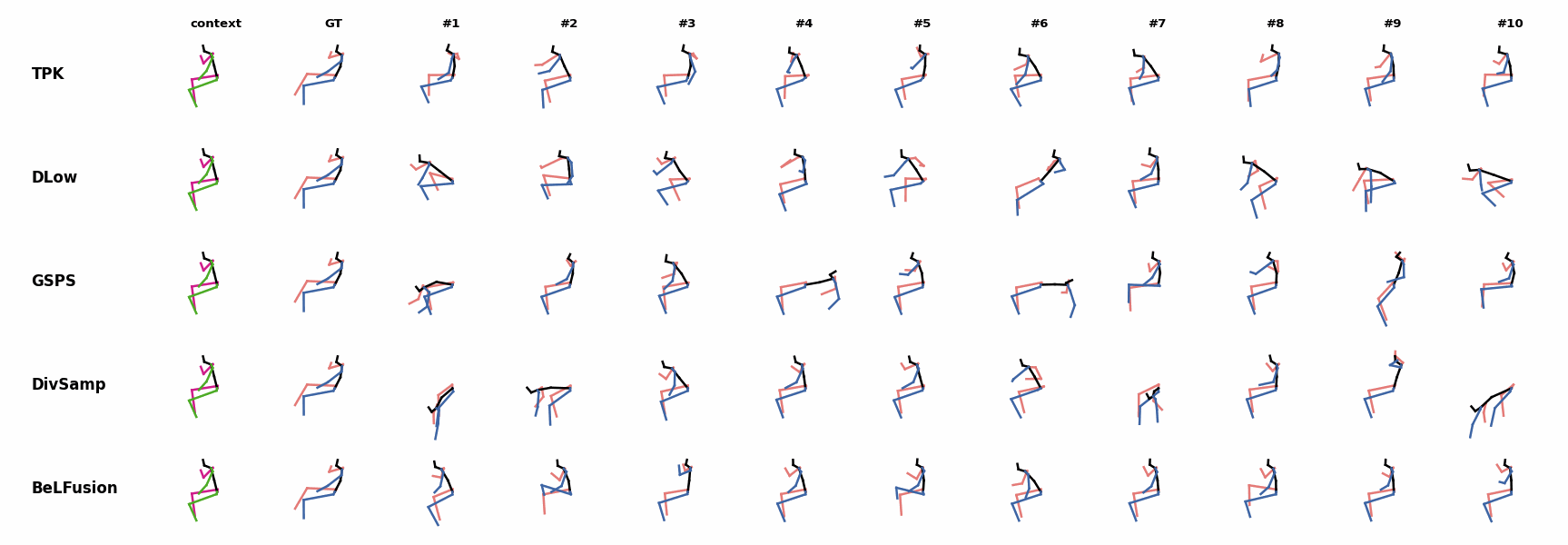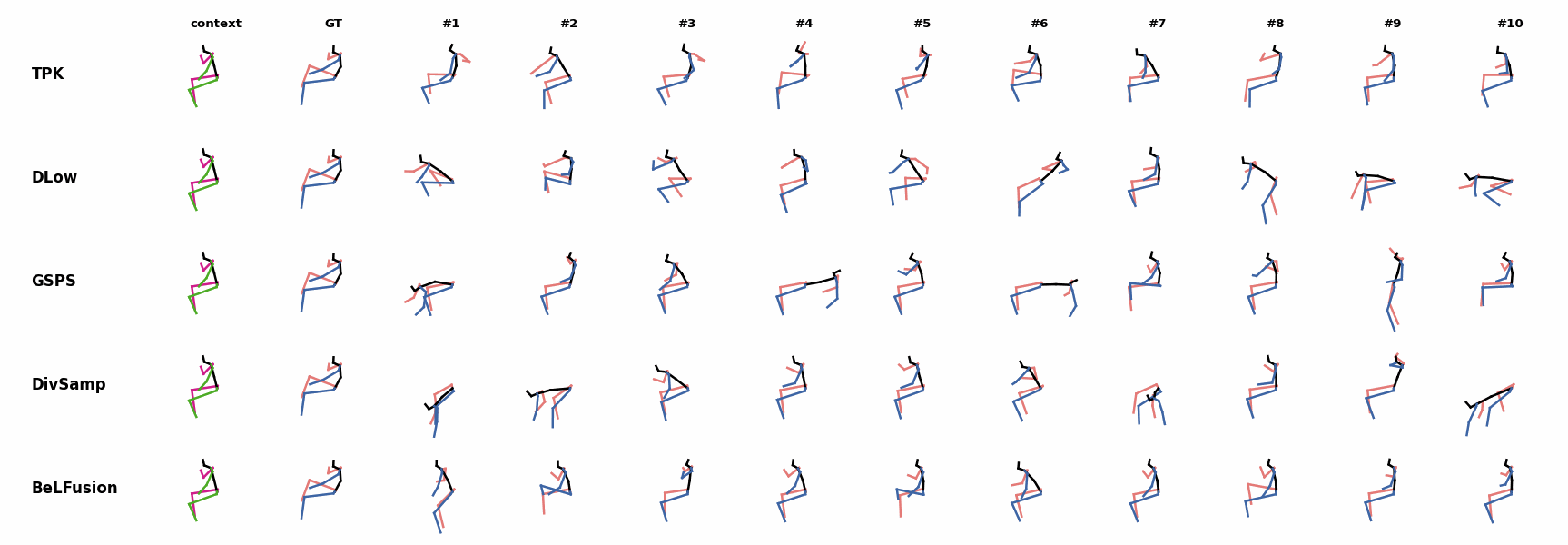 BeLFusion's predictions for sequences where the arms are used in an ongoing action (‘H_402_Smoking’, ‘H_446_Smoking’, and ‘H_541_Phoning’) have a more limited variety of arms motion.
BeLFusion's predictions for sequences where the arms are used in an ongoing action (‘H_402_Smoking’, ‘H_446_Smoking’, and ‘H_541_Phoning’) have a more limited variety of arms motion.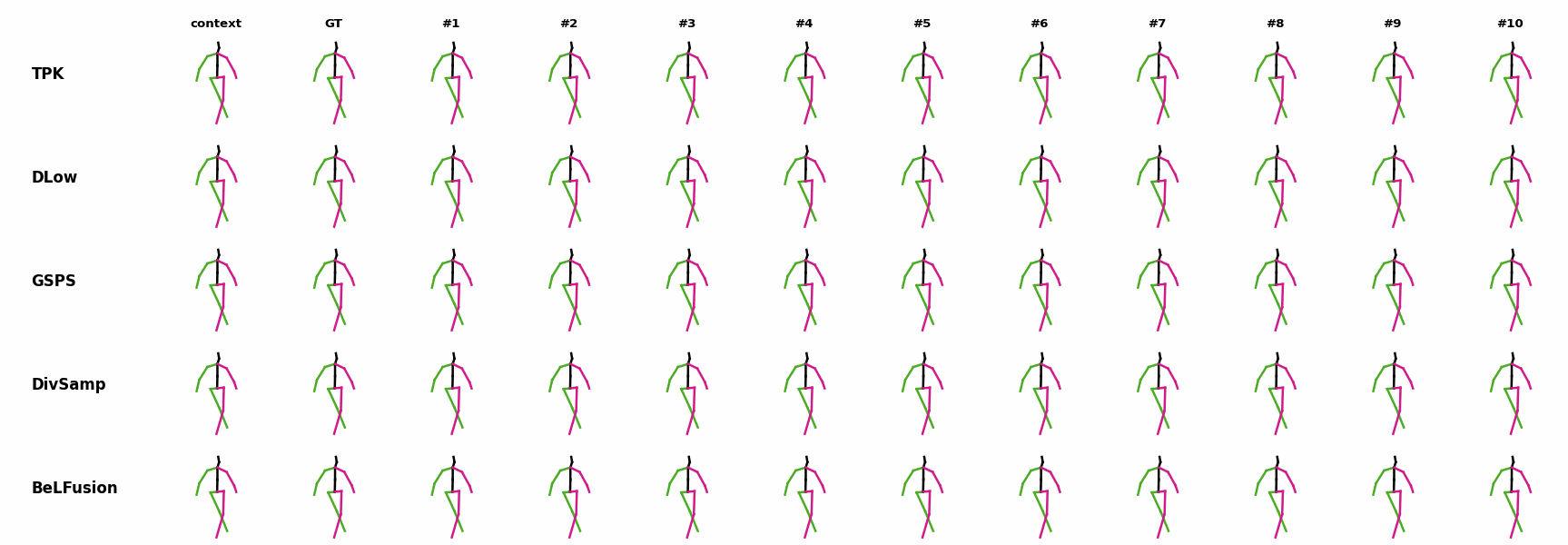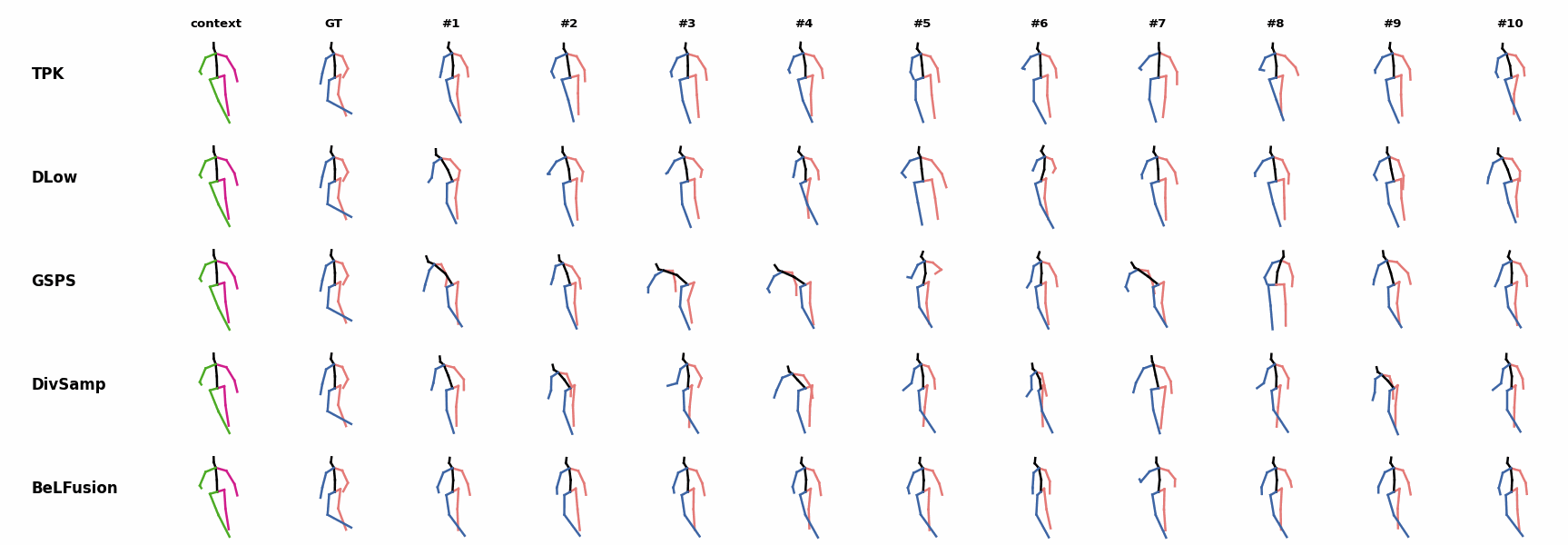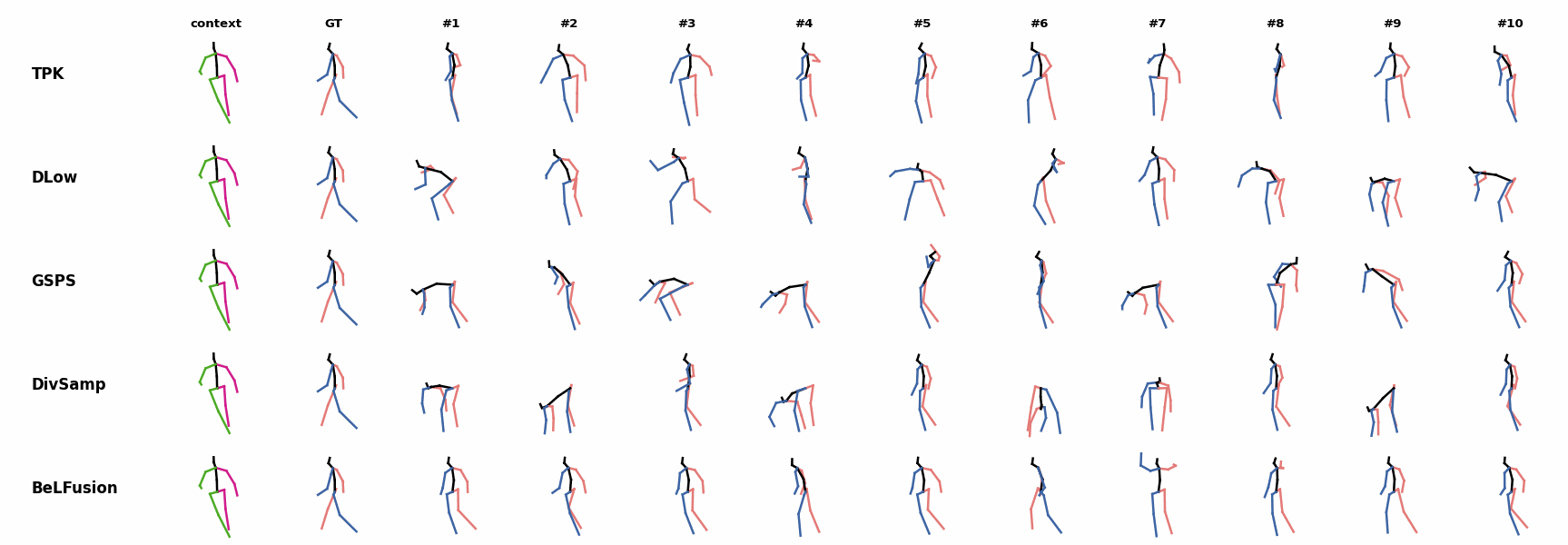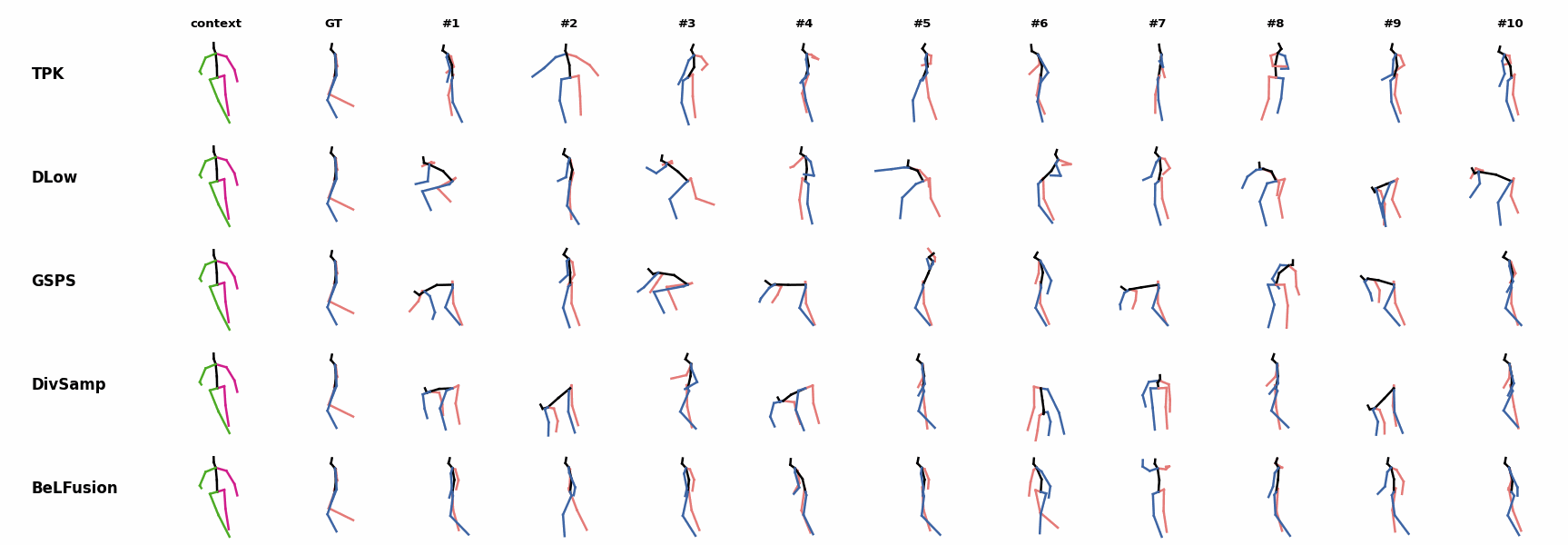 When the observation shows an ongoing fast motion, BeLFusion is the only model that consistently generates a coherent transition between the observation and the predicted behavior. Other methods mostly predict a sudden stop of the previous action.
When the observation shows an ongoing fast motion, BeLFusion is the only model that consistently generates a coherent transition between the observation and the predicted behavior. Other methods mostly predict a sudden stop of the previous action.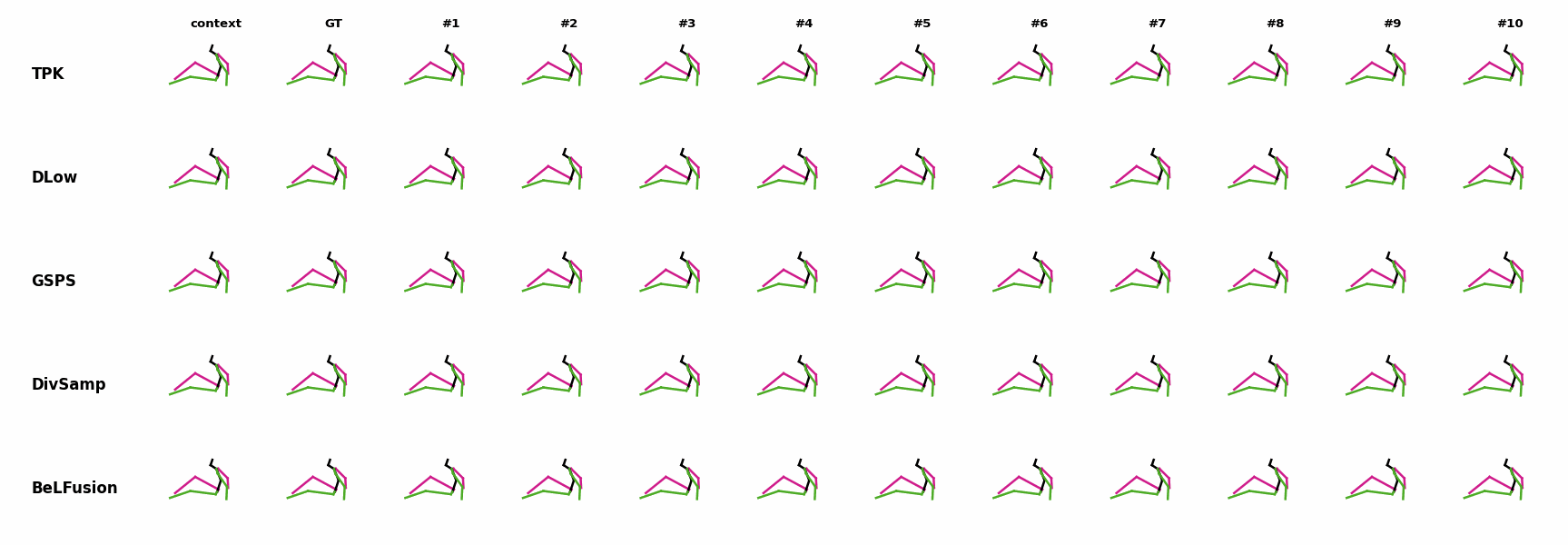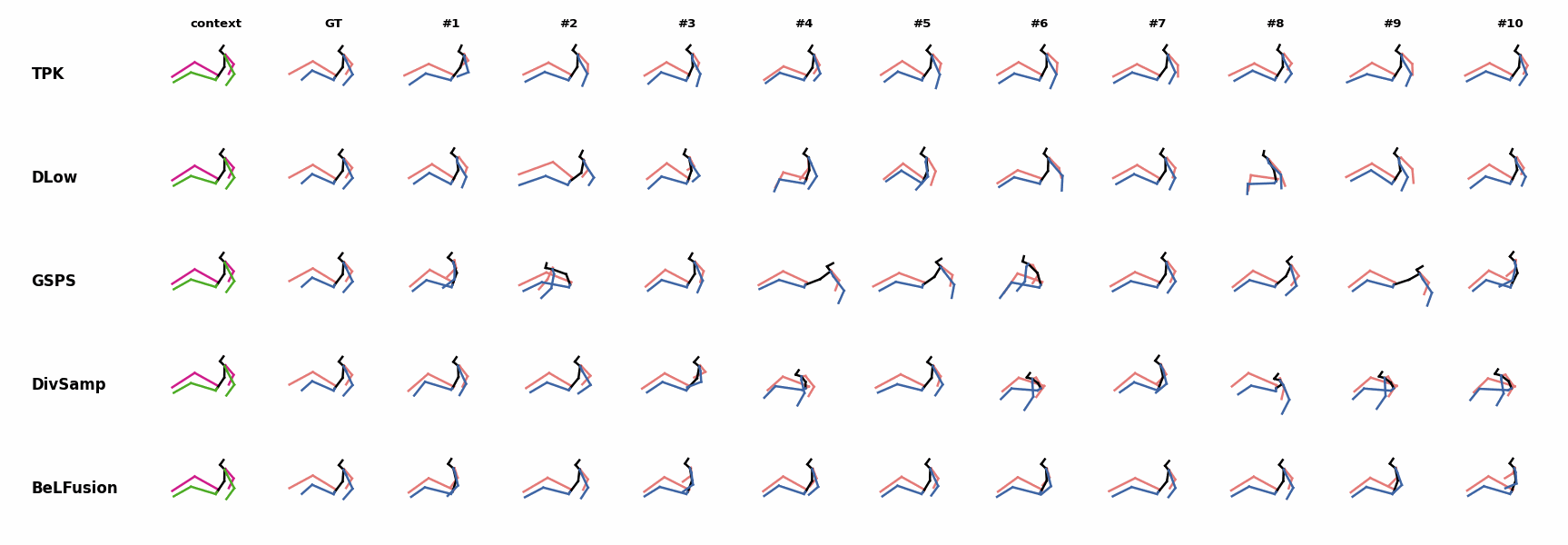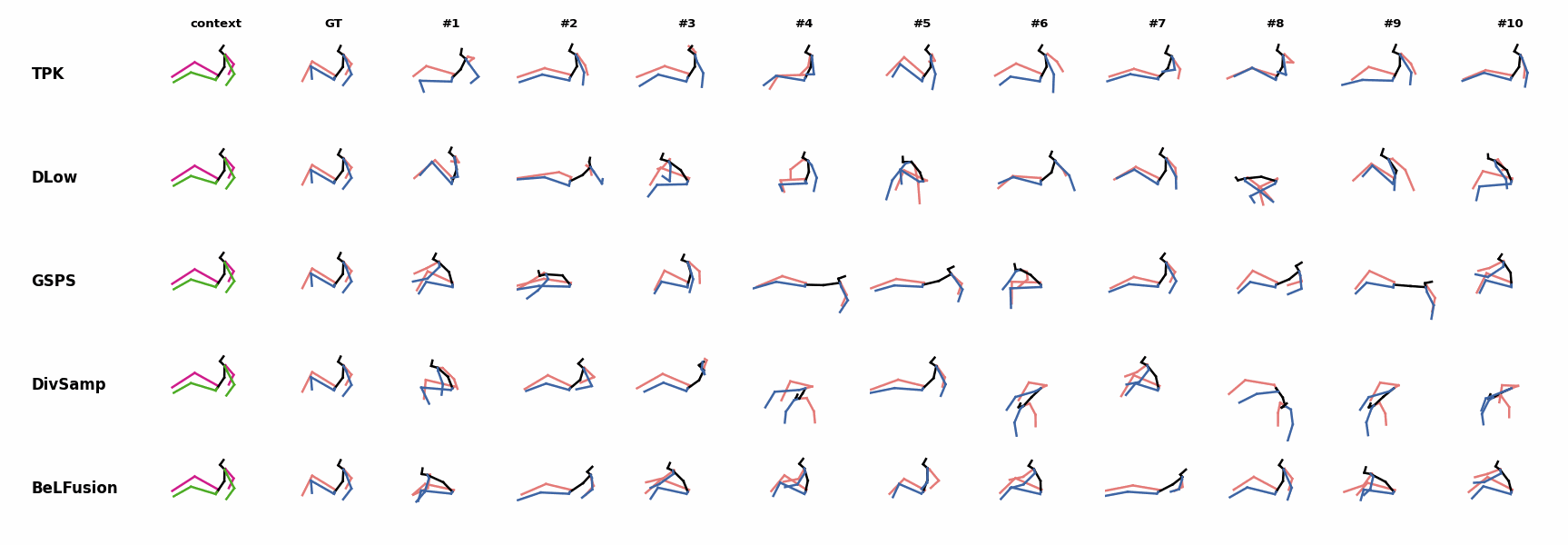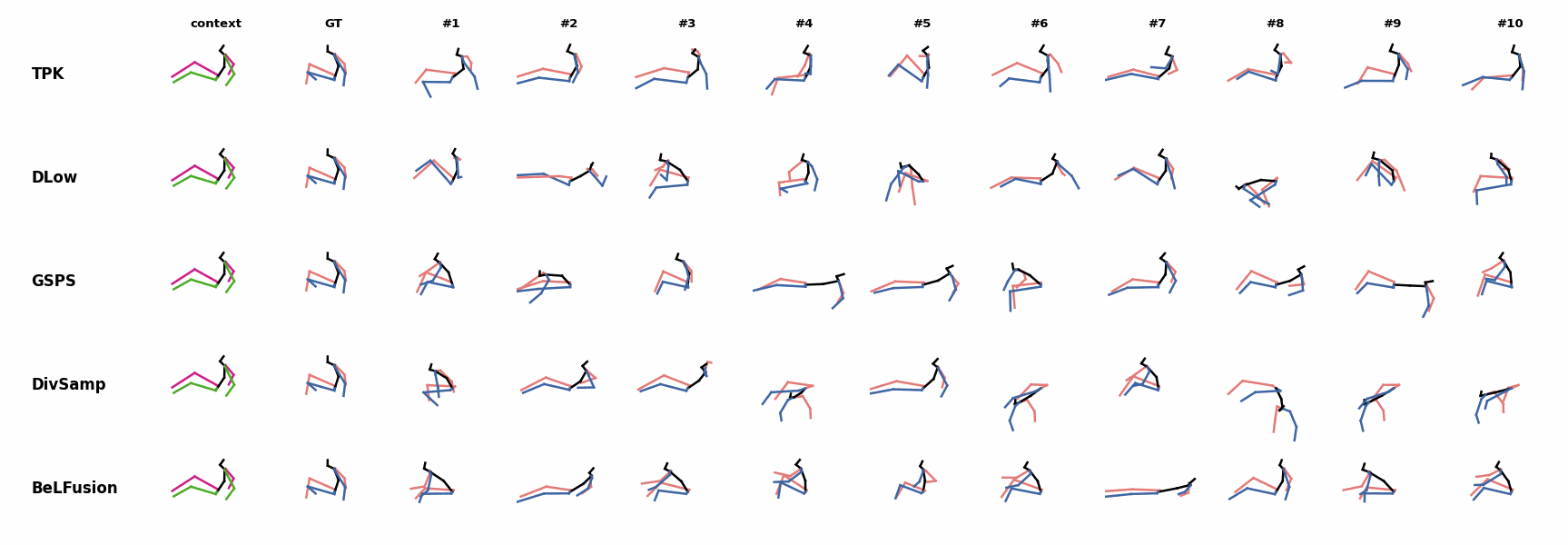 In general, BeLFusion provides good coverage of all plausible futures given the contextual setting. In this example, our model’s predictions contain as many different actions as all other methods, with no realism trade-off as for GSPS or DivSamp.
In general, BeLFusion provides good coverage of all plausible futures given the contextual setting. In this example, our model’s predictions contain as many different actions as all other methods, with no realism trade-off as for GSPS or DivSamp.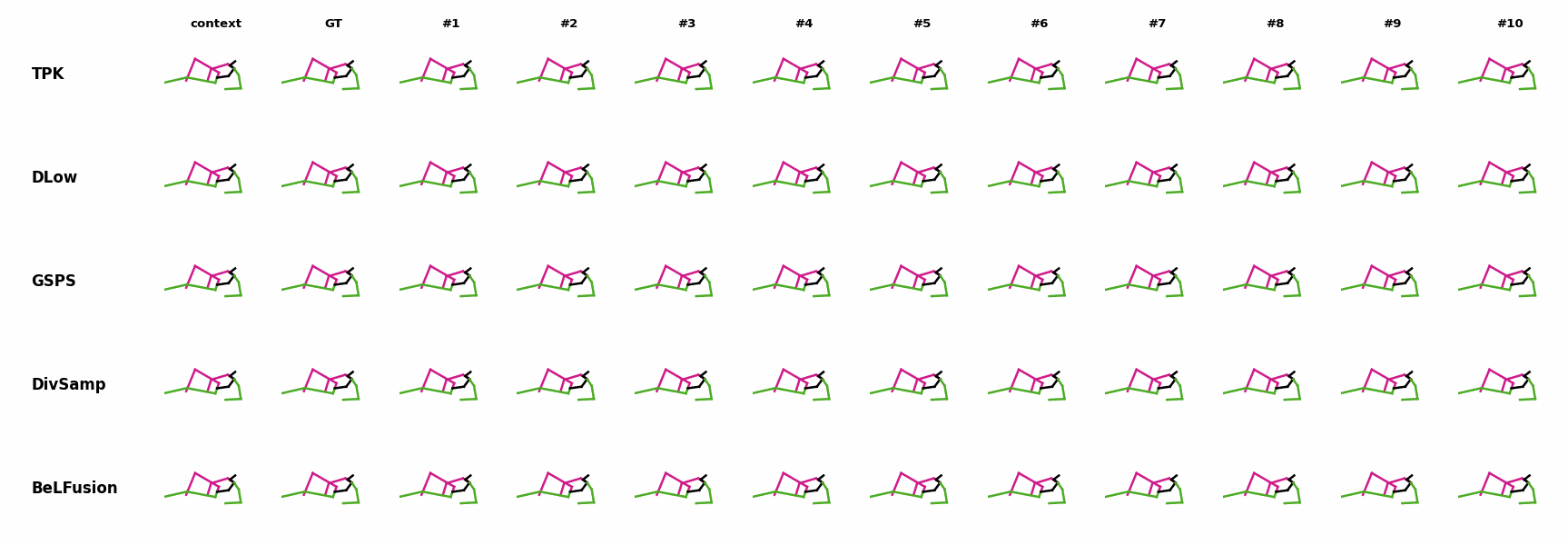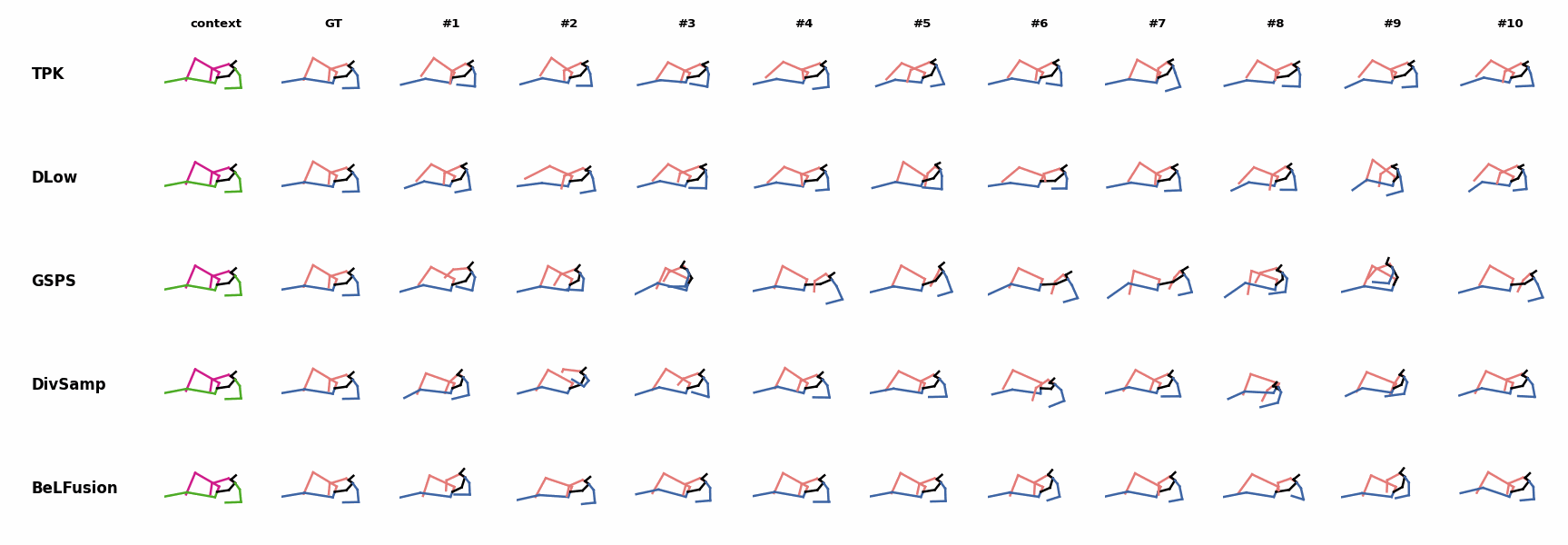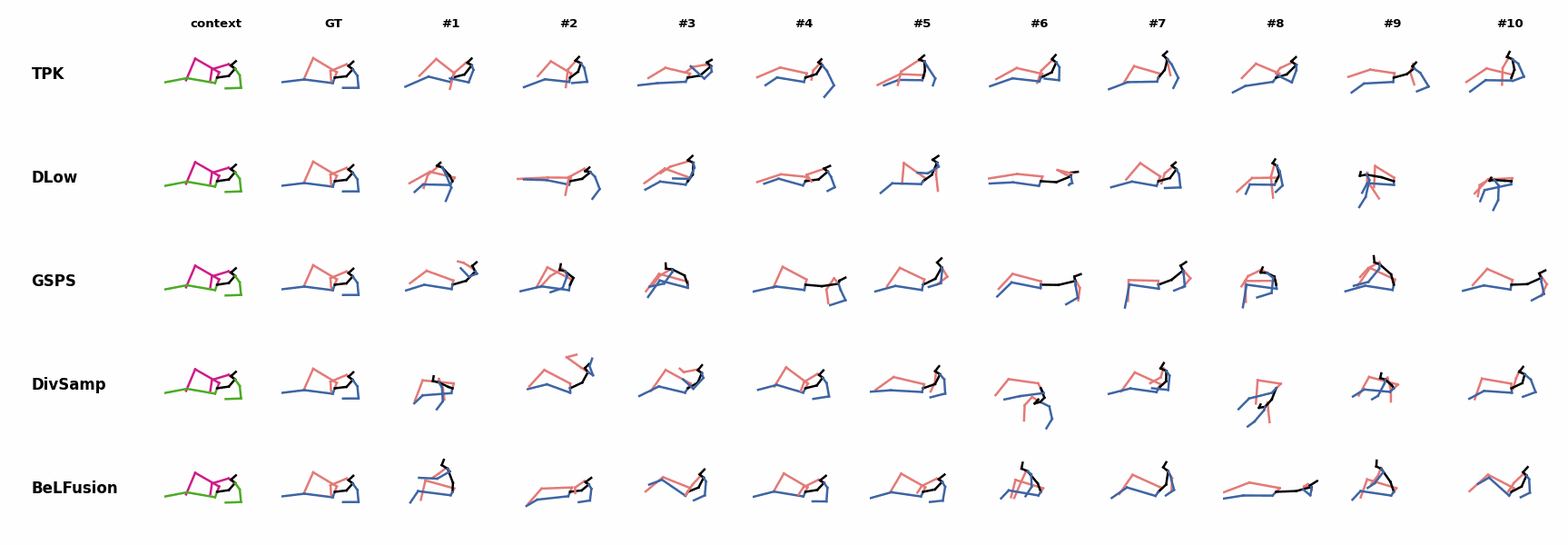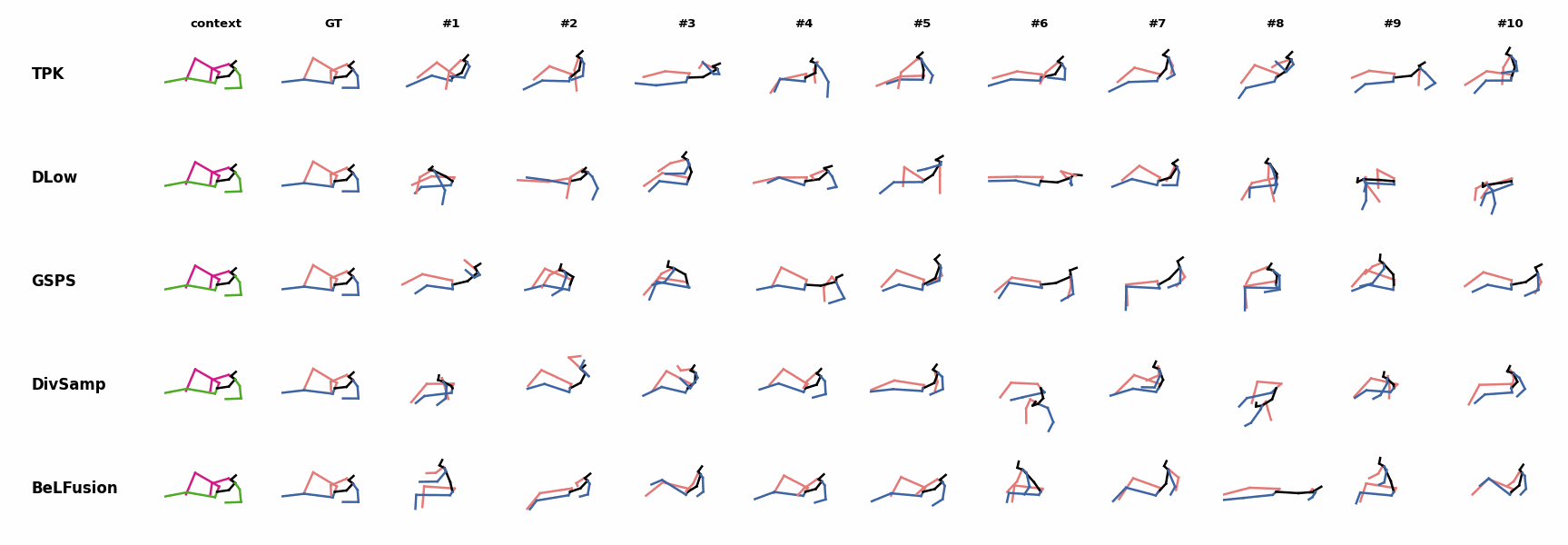 In general, BeLFusion provides good coverage of all plausible futures given the contextual setting. In this example, our model’s predictions contain as many different actions as all other methods, with no realism trade-off as for GSPS or DivSamp.
In general, BeLFusion provides good coverage of all plausible futures given the contextual setting. In this example, our model’s predictions contain as many different actions as all other methods, with no realism trade-off as for GSPS or DivSamp.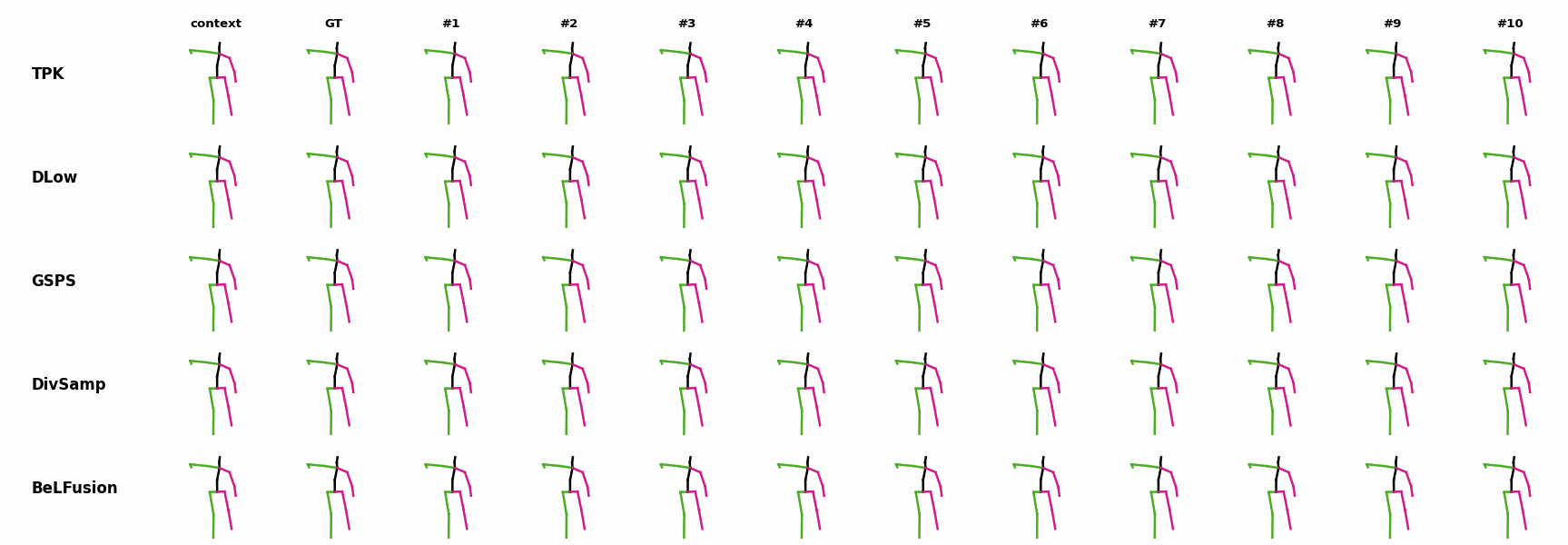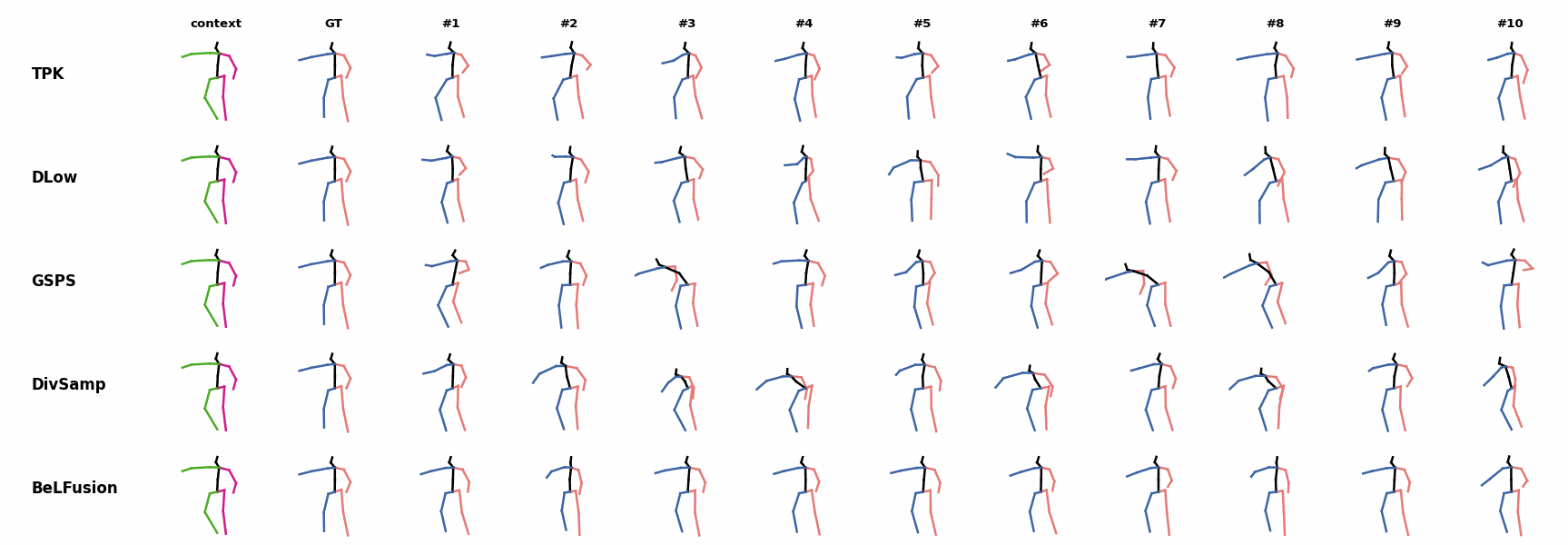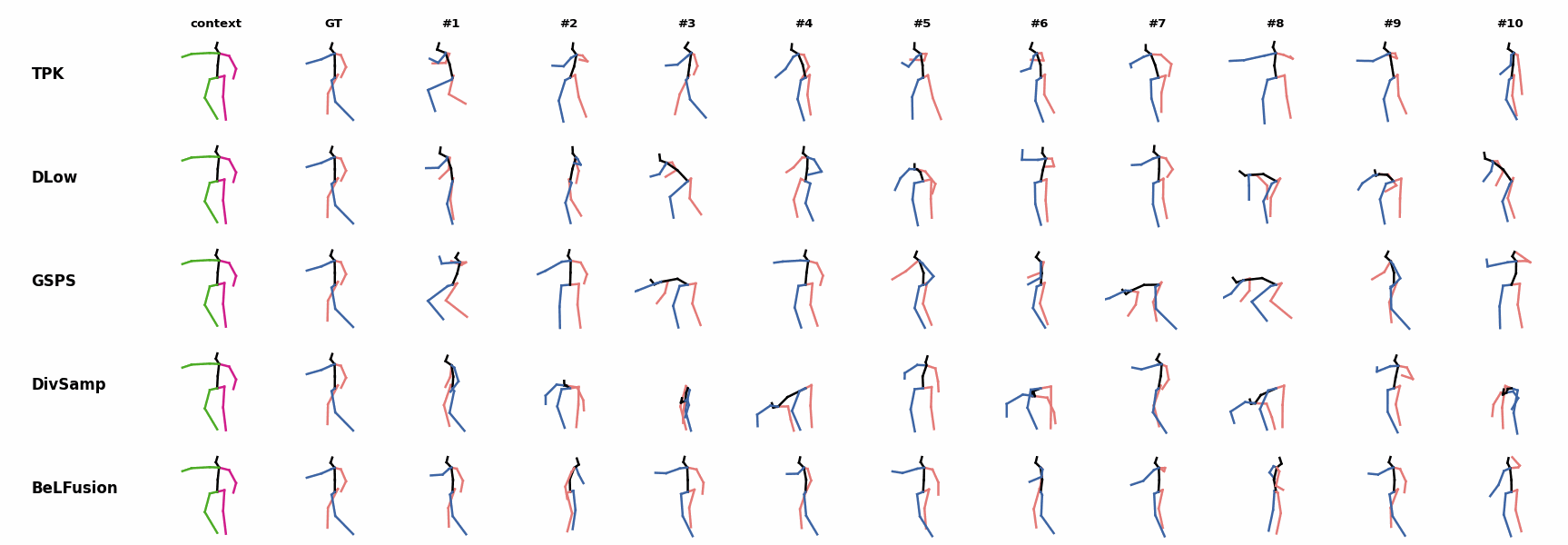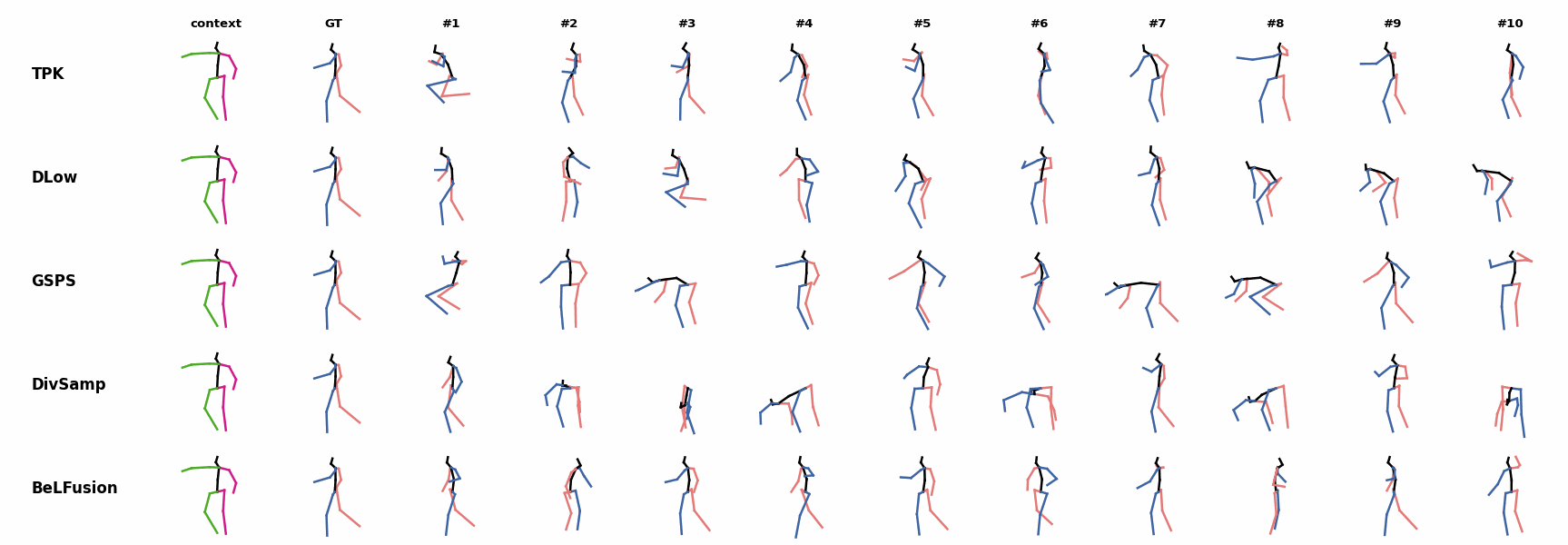 Our method predicts motions that are compatible with the ongoing action of walking next to someone, whereas other methods ignore such possibility.
Our method predicts motions that are compatible with the ongoing action of walking next to someone, whereas other methods ignore such possibility. When the observation shows an ongoing fast motion, BeLFusion is the only model that consistently generates a coherent transition between the observation and the predicted behavior. Other methods mostly predict a sudden stop of the previous action.
When the observation shows an ongoing fast motion, BeLFusion is the only model that consistently generates a coherent transition between the observation and the predicted behavior. Other methods mostly predict a sudden stop of the previous action.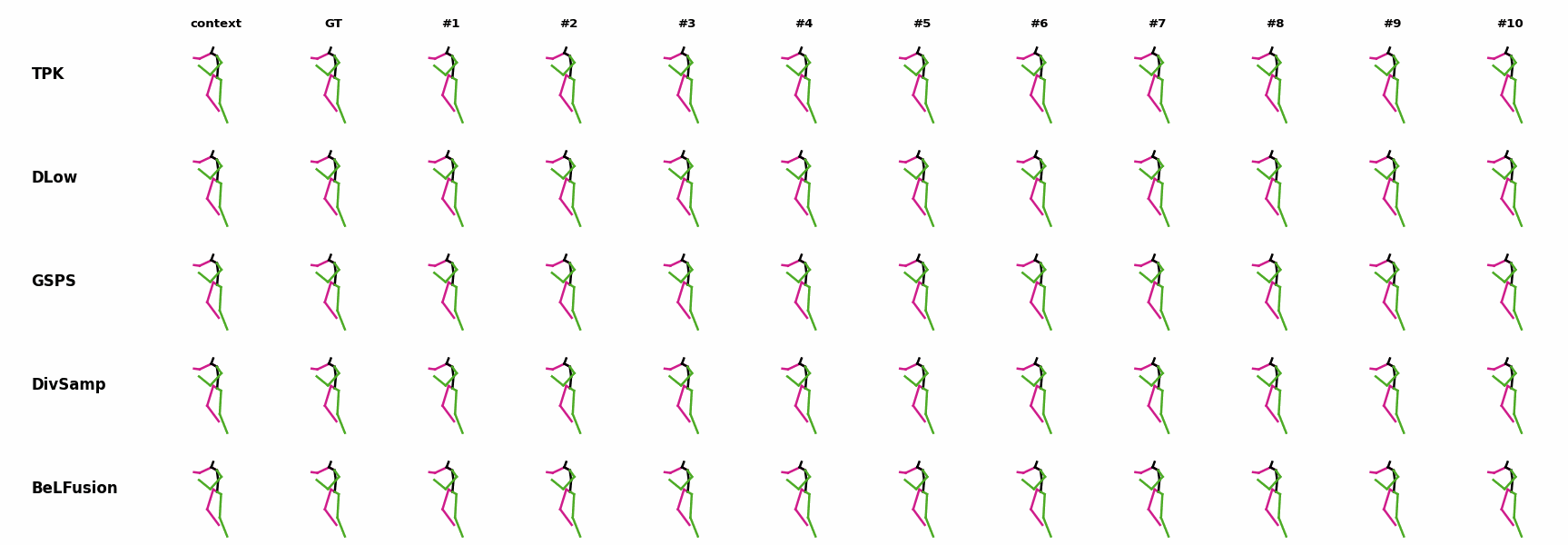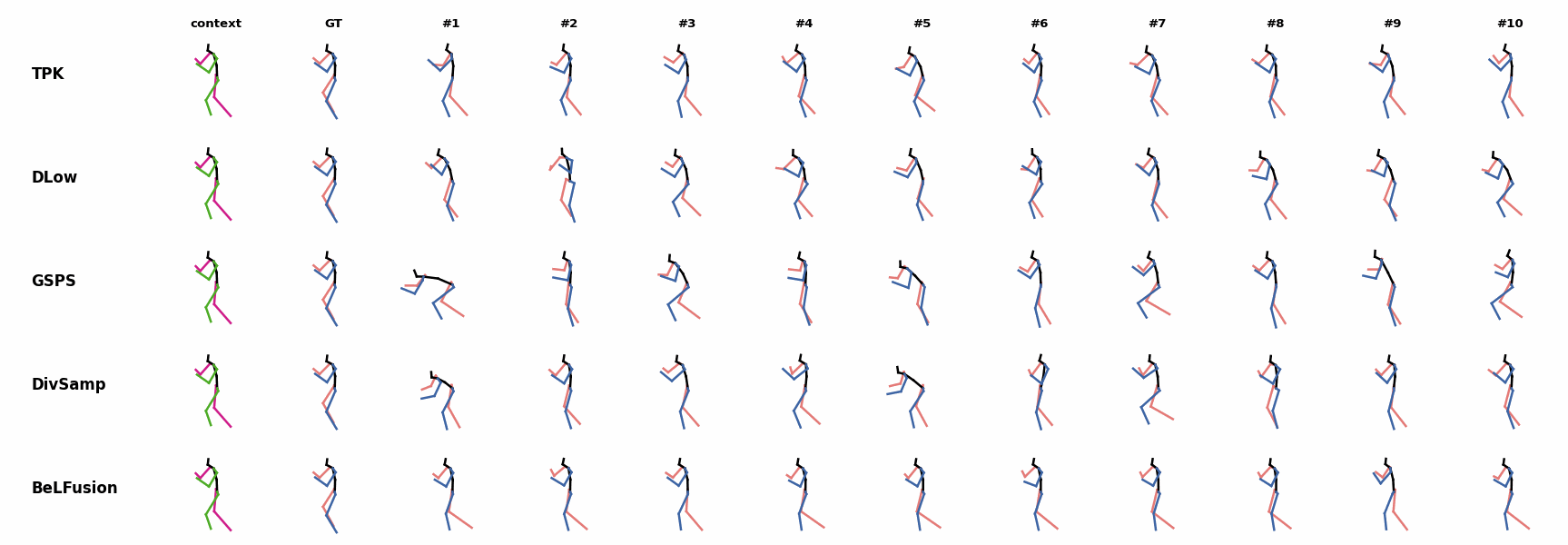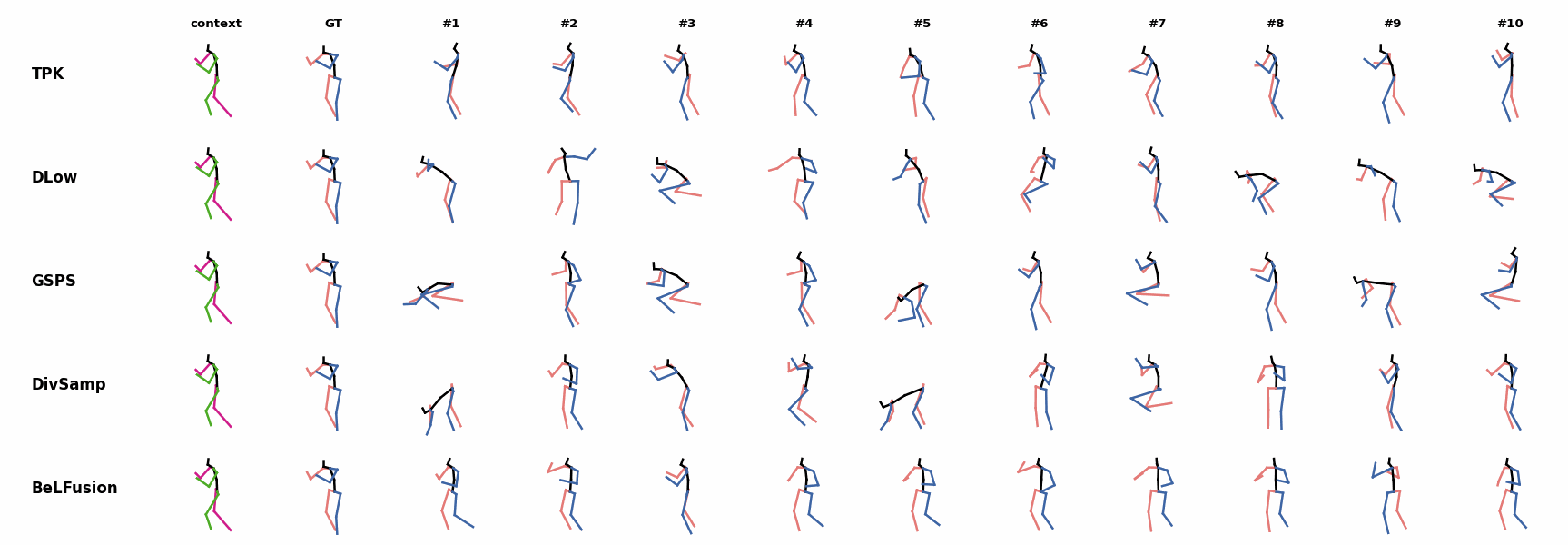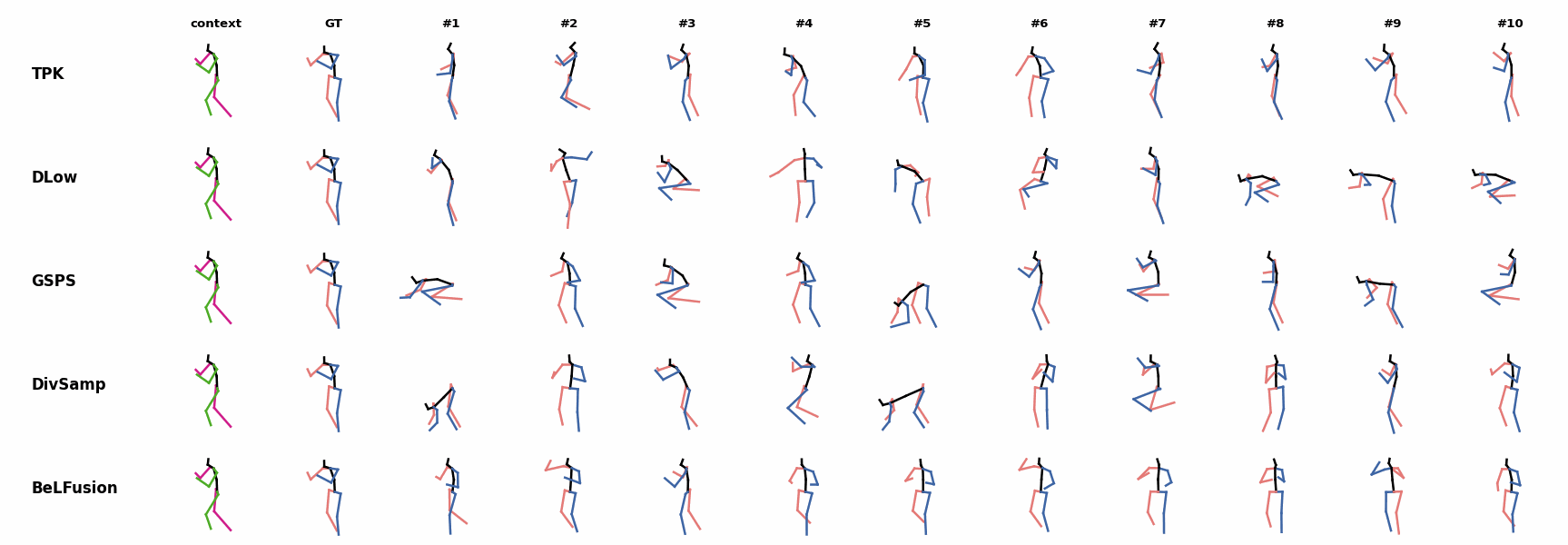 When the observation shows an ongoing fast motion, BeLFusion is the only model that consistently generates a coherent transition between the observation and the predicted behavior. Other methods mostly predict a sudden stop of the previous action.
When the observation shows an ongoing fast motion, BeLFusion is the only model that consistently generates a coherent transition between the observation and the predicted behavior. Other methods mostly predict a sudden stop of the previous action.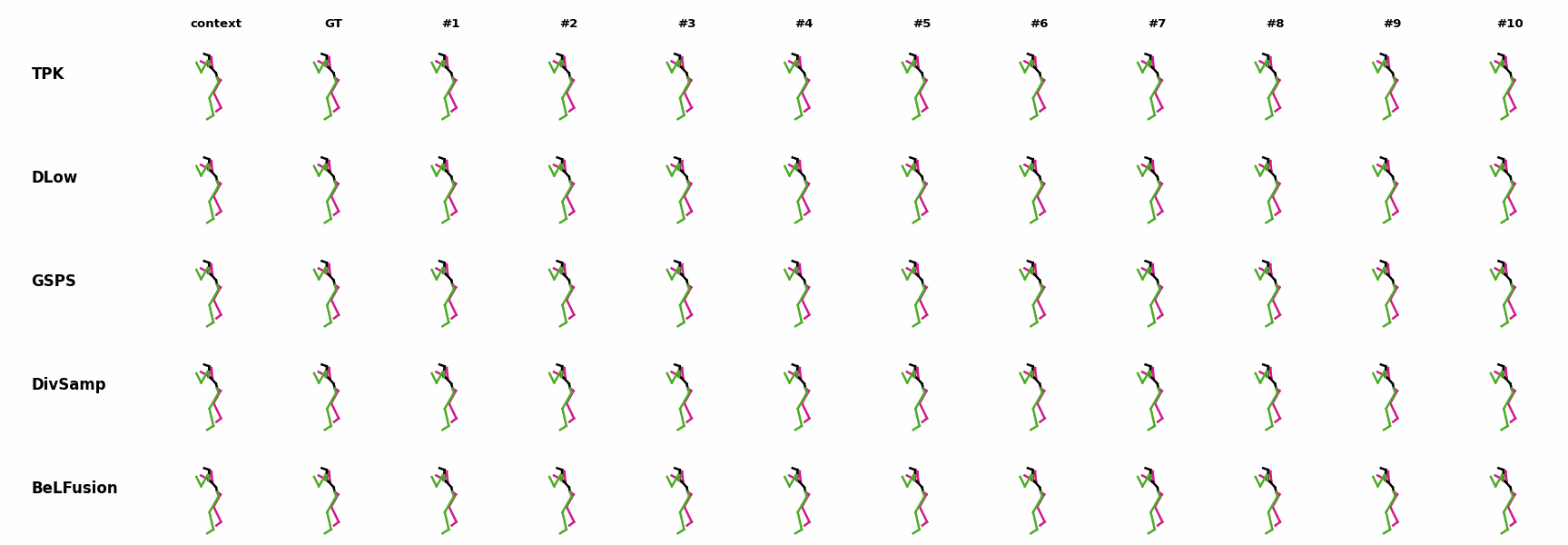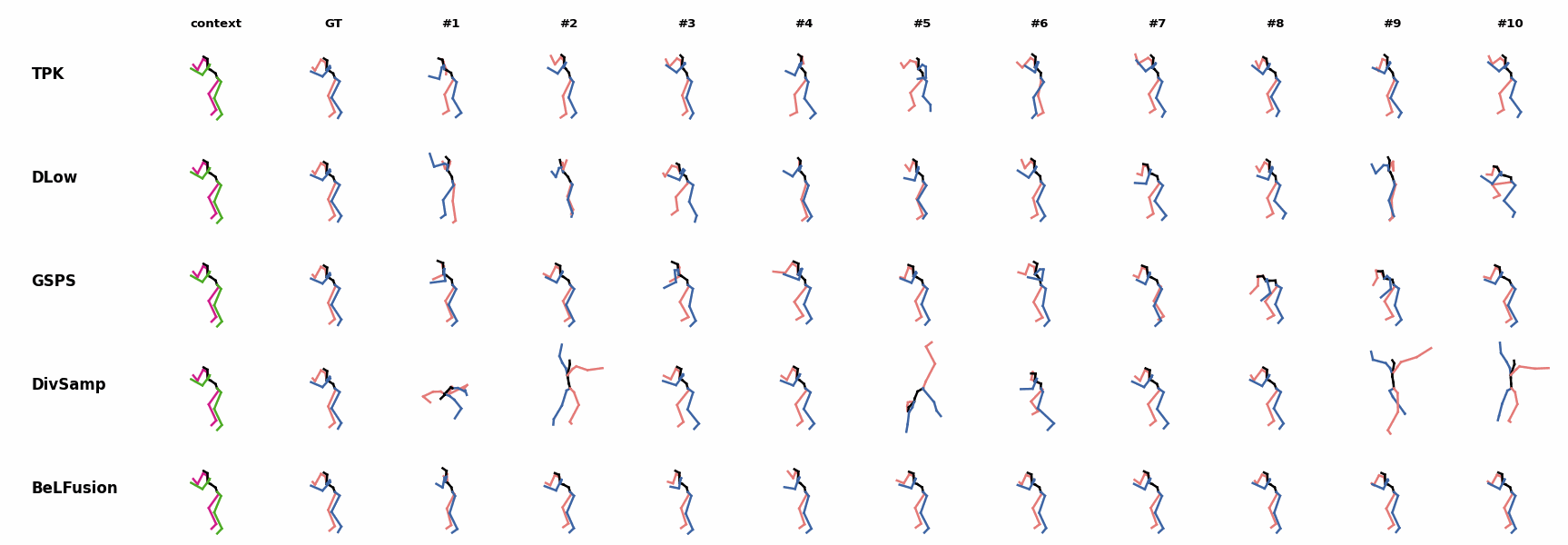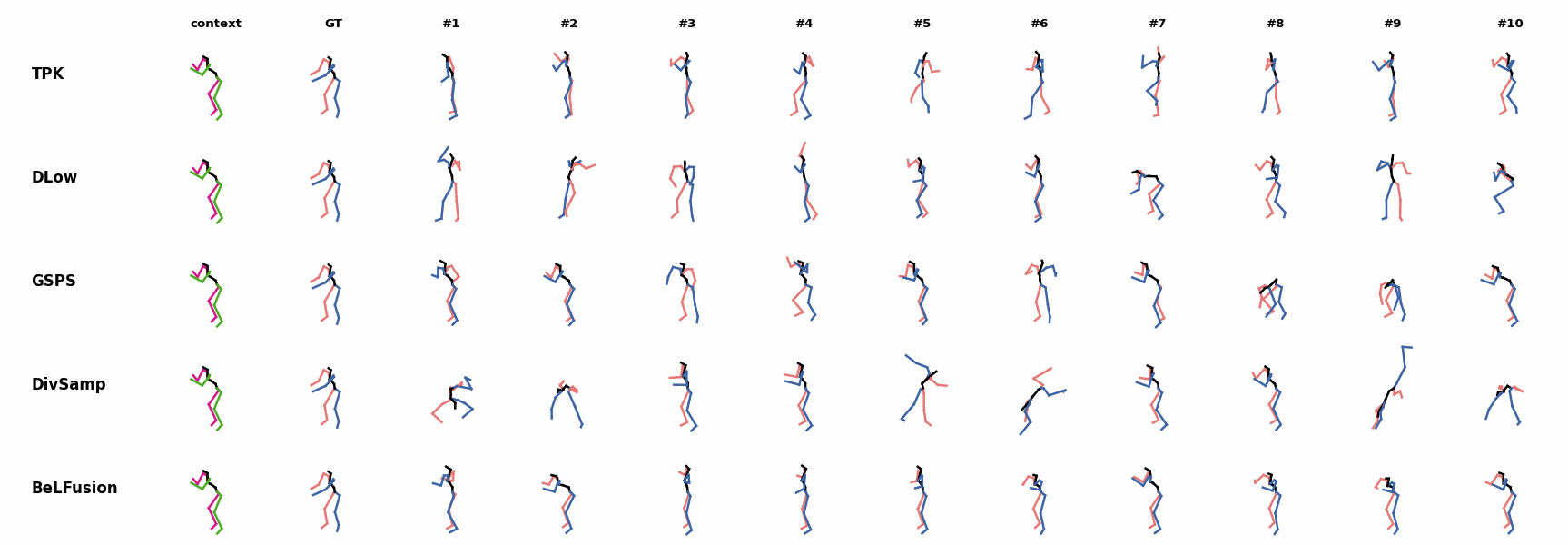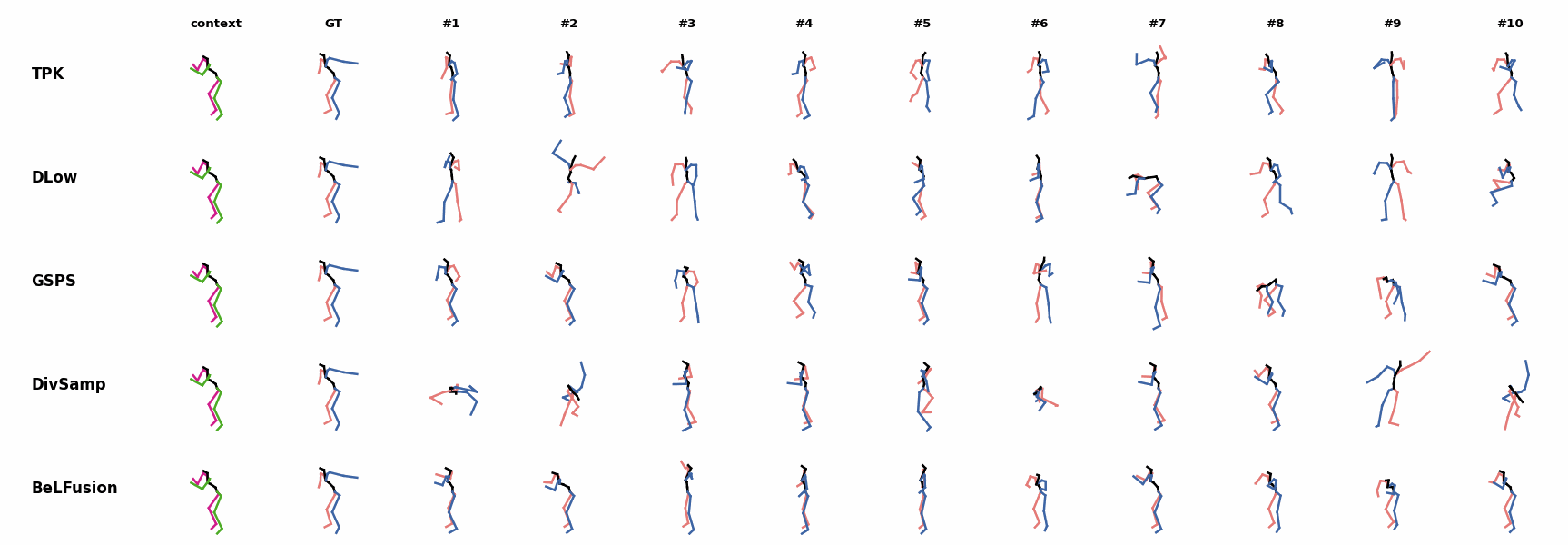 Similarly to the other state-of-the-art methods, BeLFusion also struggles with modeling high-frequencies.
Similarly to the other state-of-the-art methods, BeLFusion also struggles with modeling high-frequencies.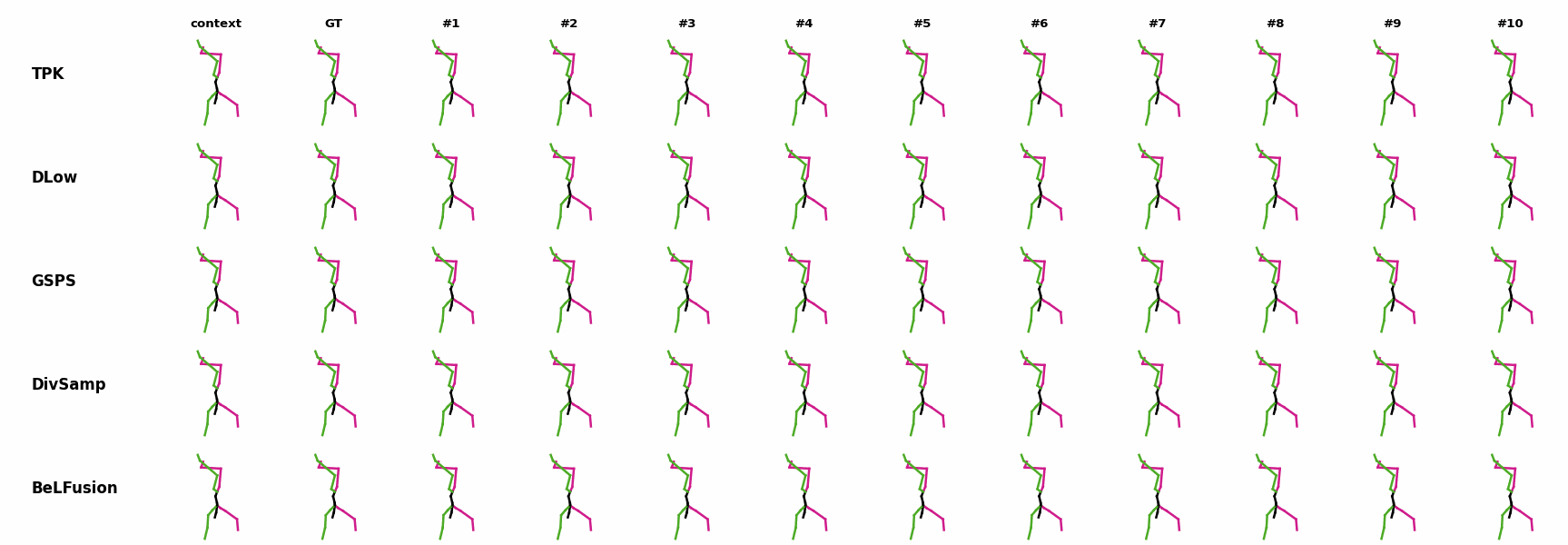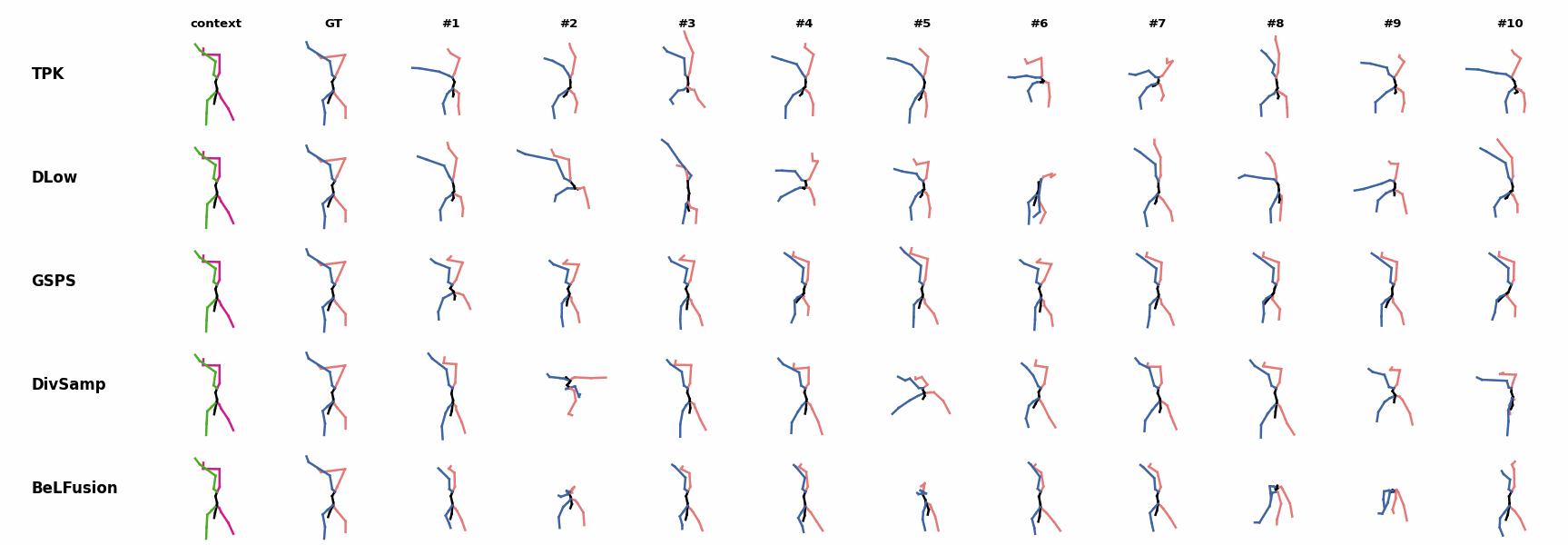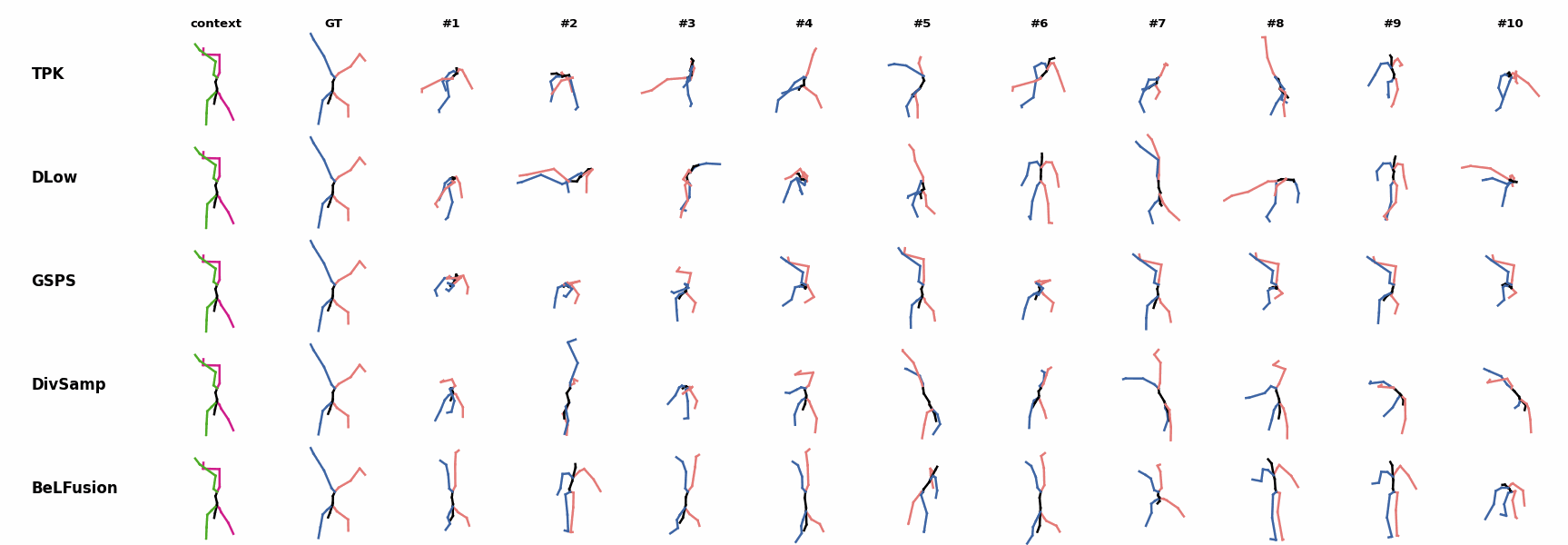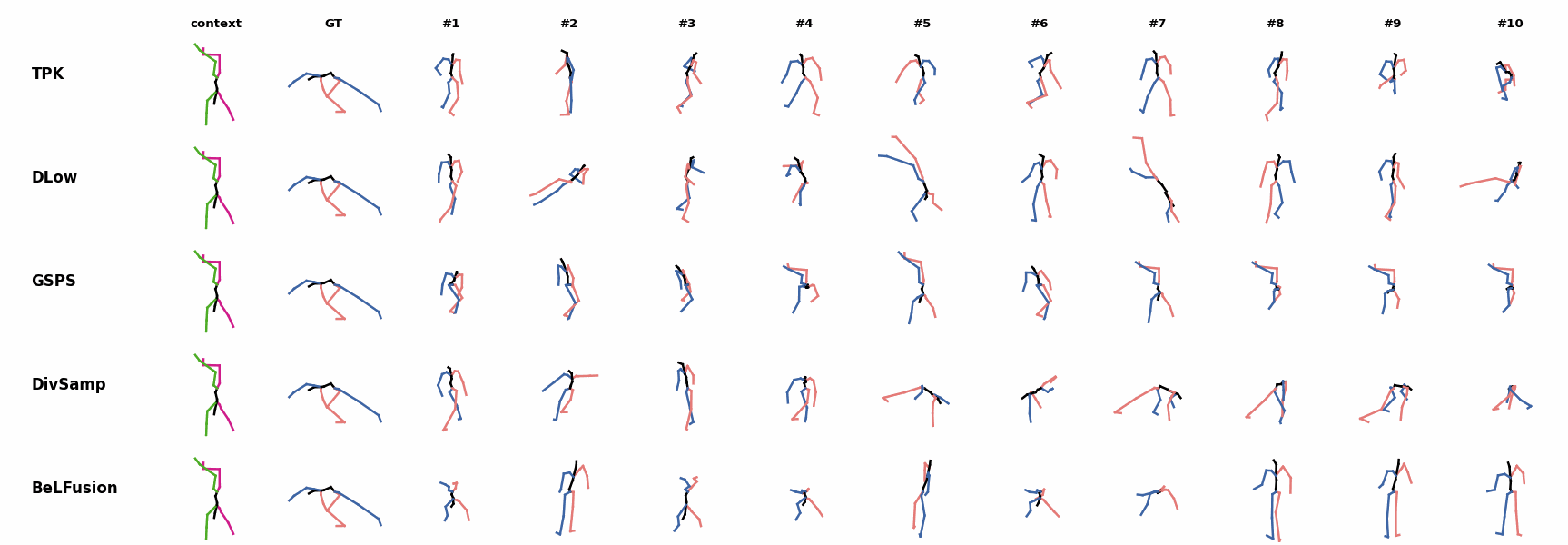 The first-seen handstand behavior in the observation leads to BeLFusion generating several wrong movement continuations. The fast legs motion during the observation is not reflected in any prediction, although BeLFusion slightly shows it in samples #4 and #7.
The first-seen handstand behavior in the observation leads to BeLFusion generating several wrong movement continuations. The fast legs motion during the observation is not reflected in any prediction, although BeLFusion slightly shows it in samples #4 and #7.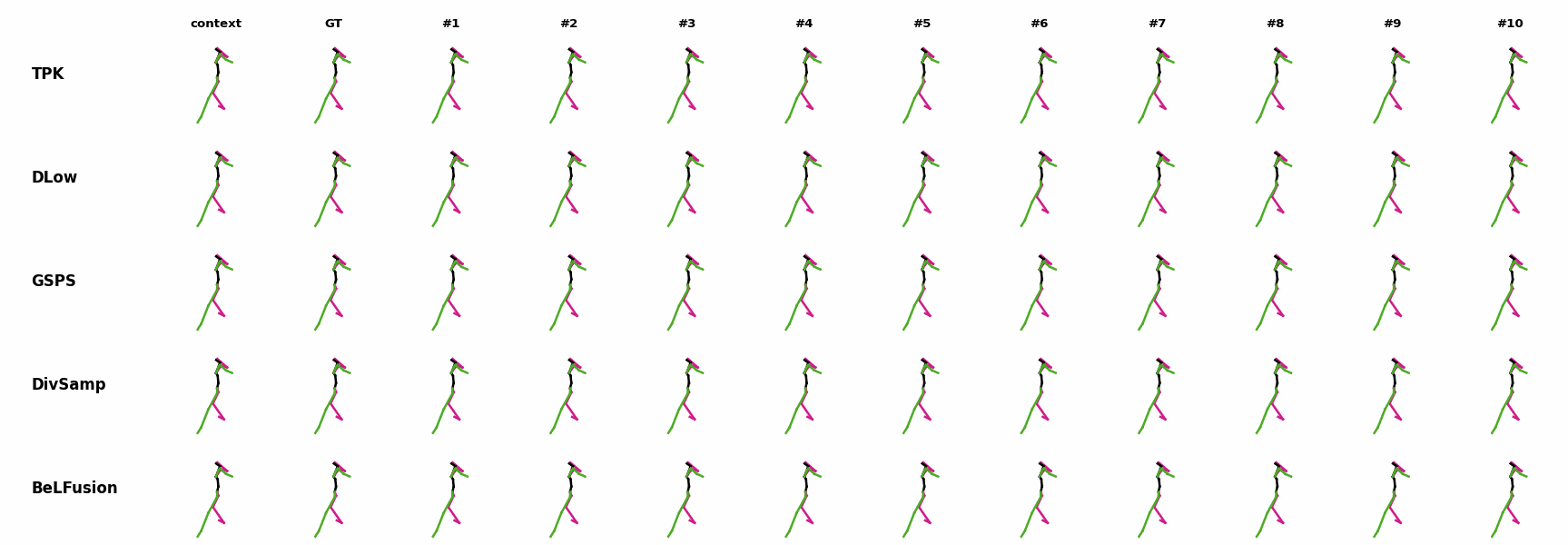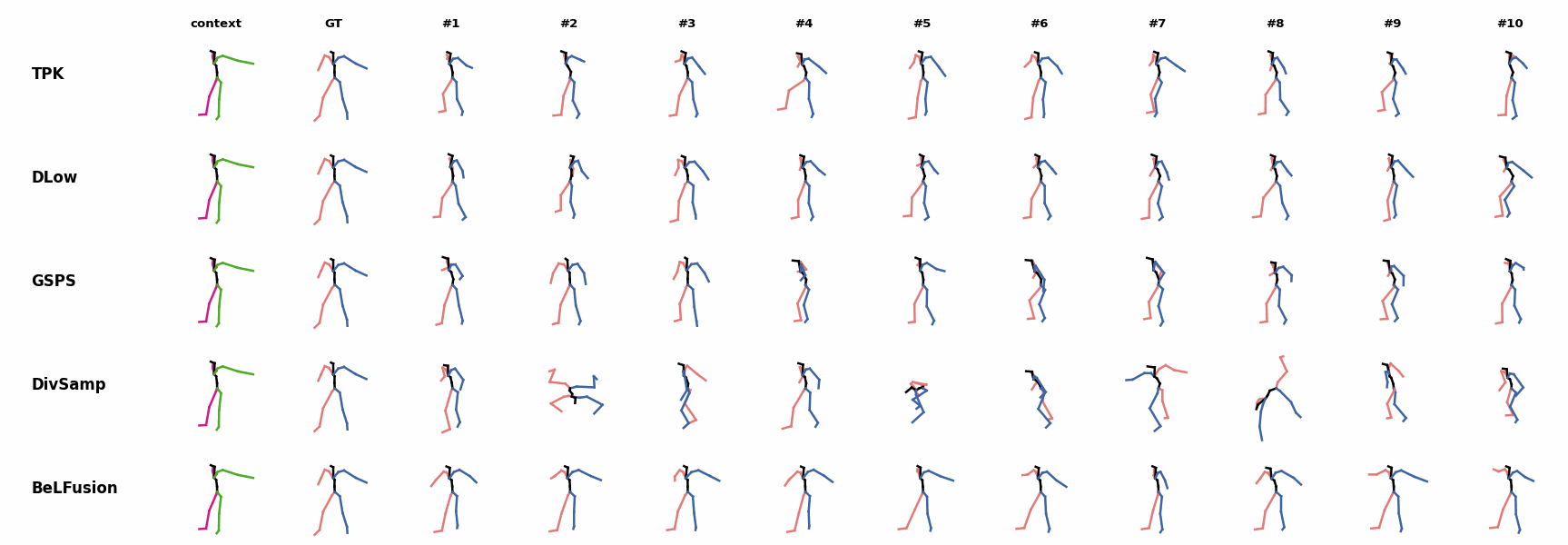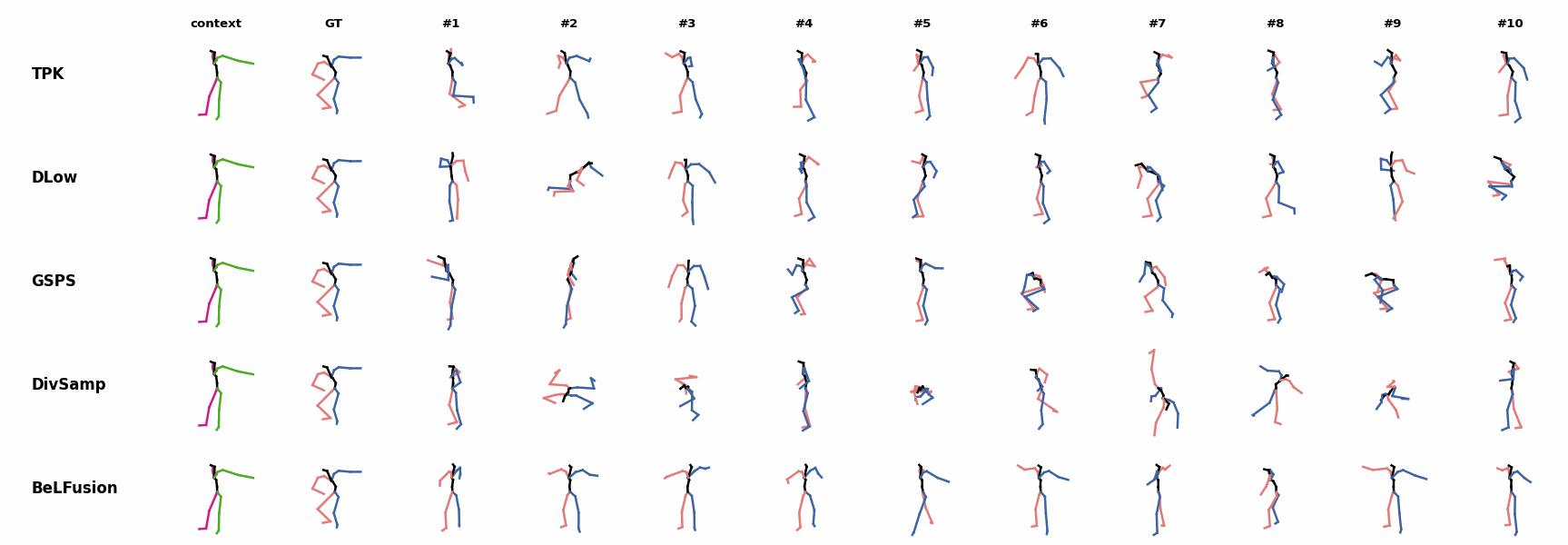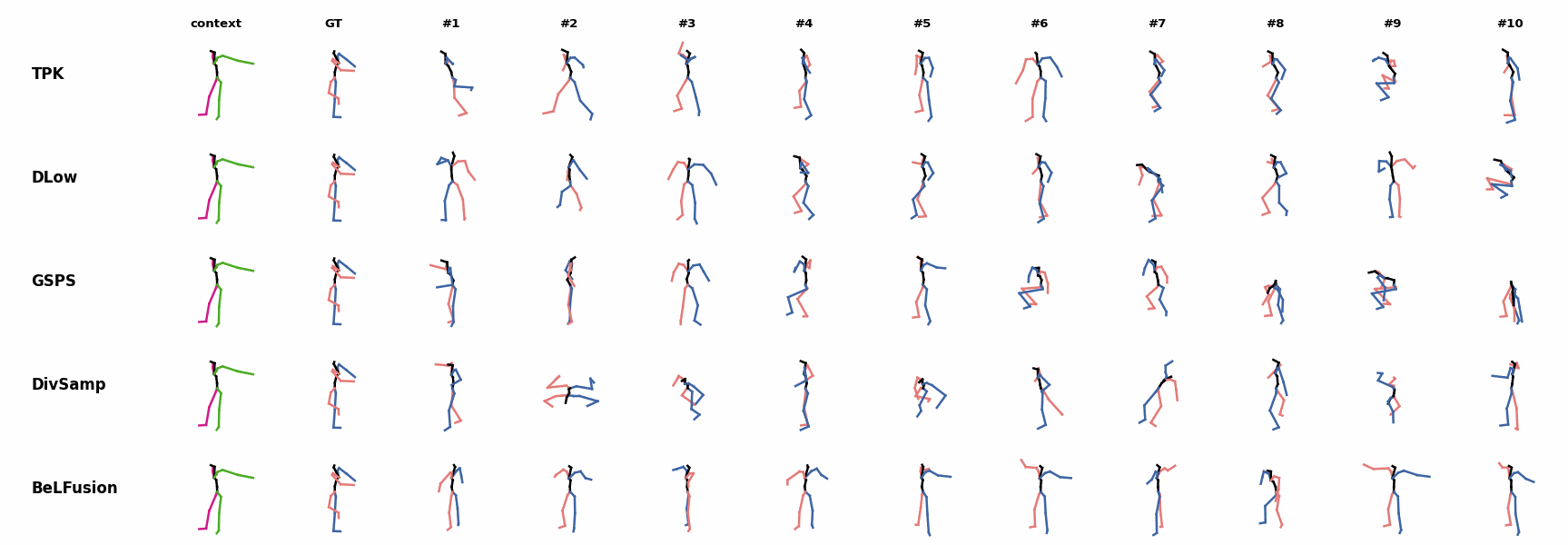 BeLFusion is able to detect that the dance moves involve keeping the arms arising while moving or rotating. In comparison, DLow, GSPS, and DivSamp simply predict other unrelated movements. TPK is only able to predict a few samples with fairly good continuations to the dance step.
BeLFusion is able to detect that the dance moves involve keeping the arms arising while moving or rotating. In comparison, DLow, GSPS, and DivSamp simply predict other unrelated movements. TPK is only able to predict a few samples with fairly good continuations to the dance step.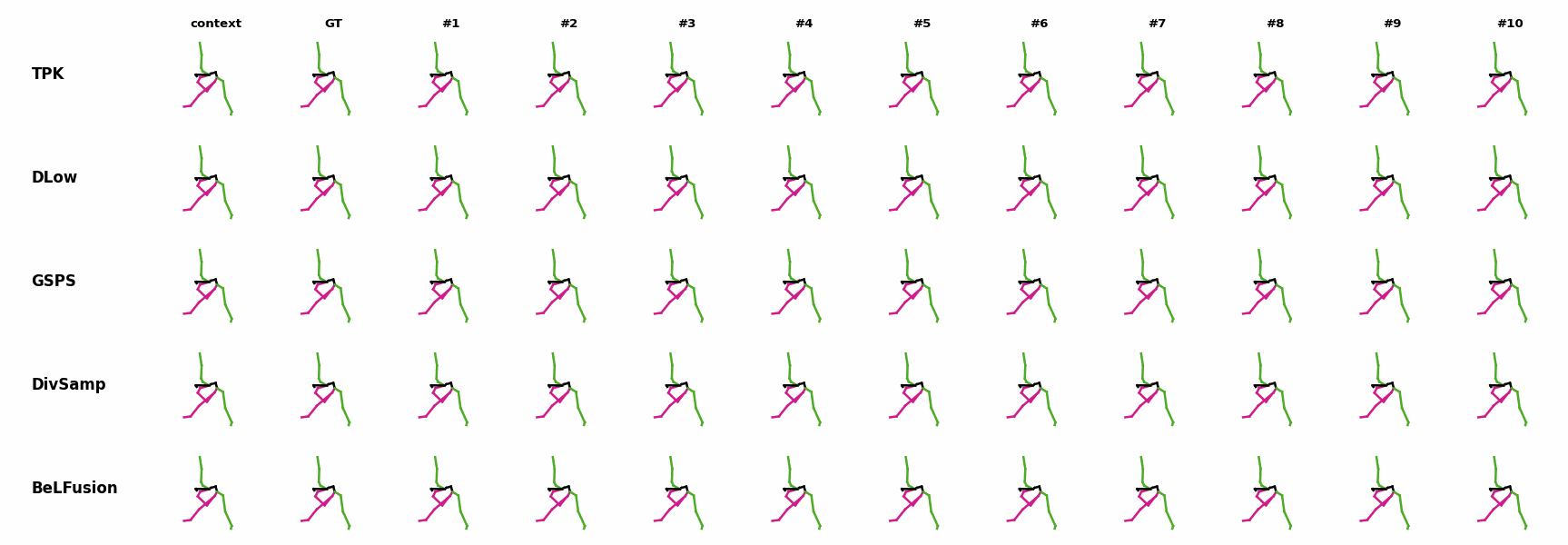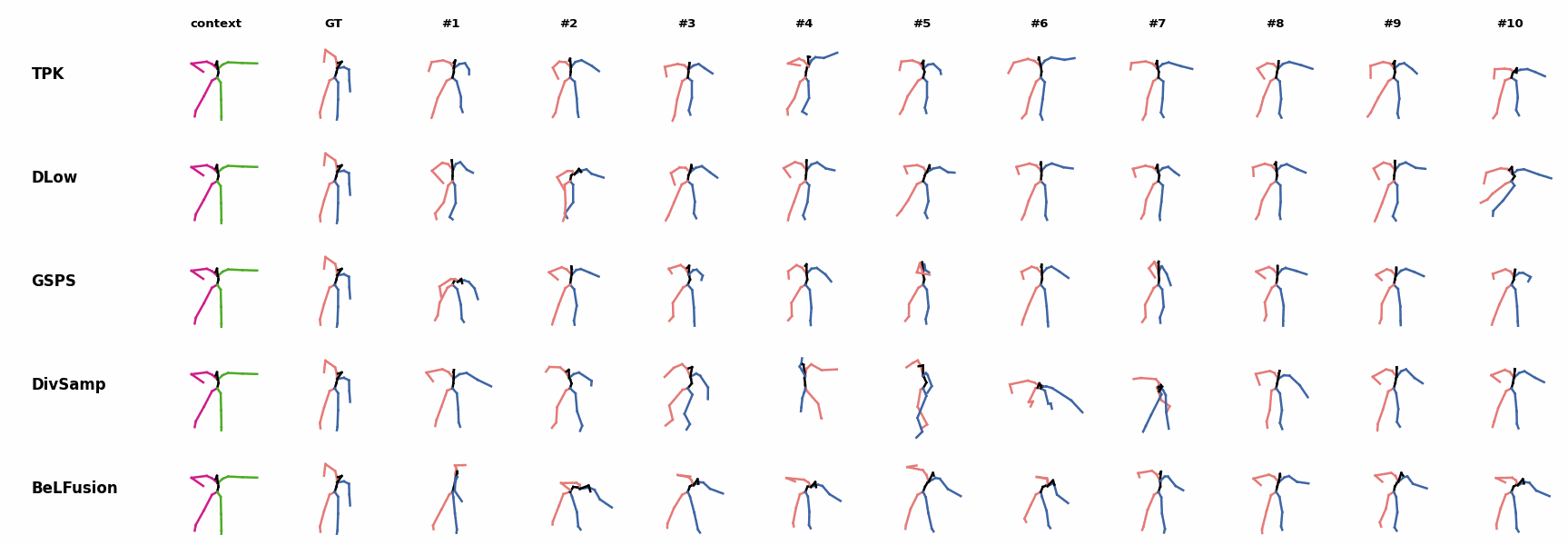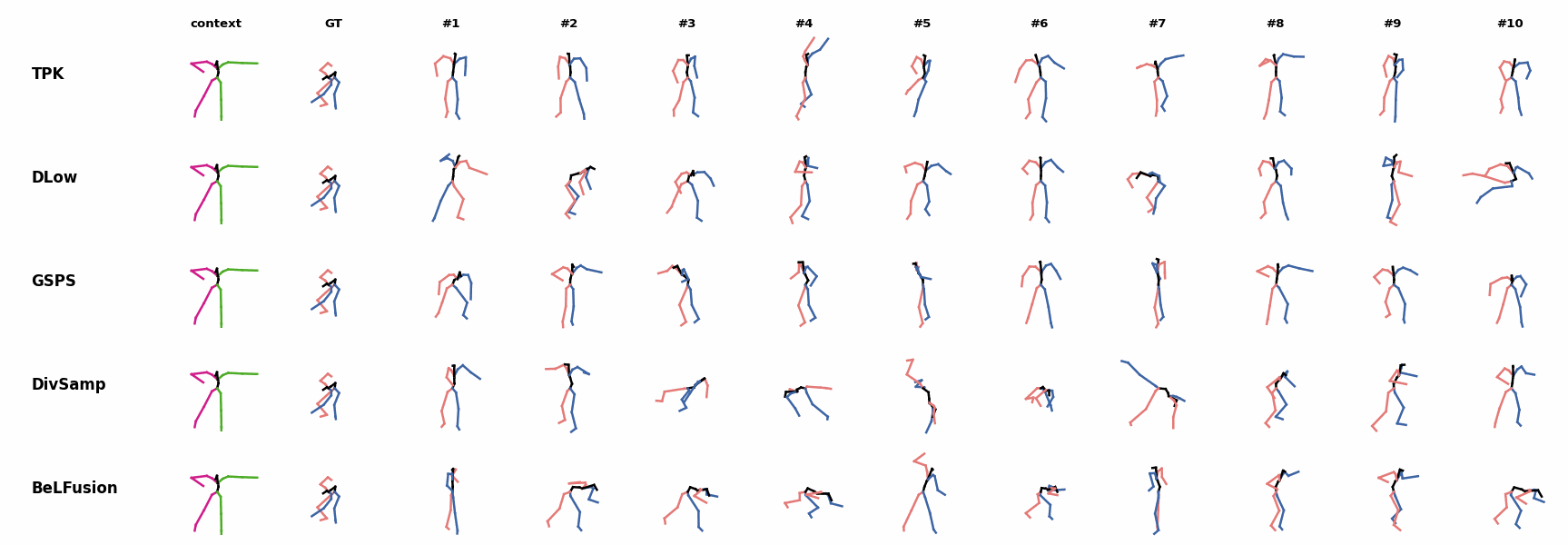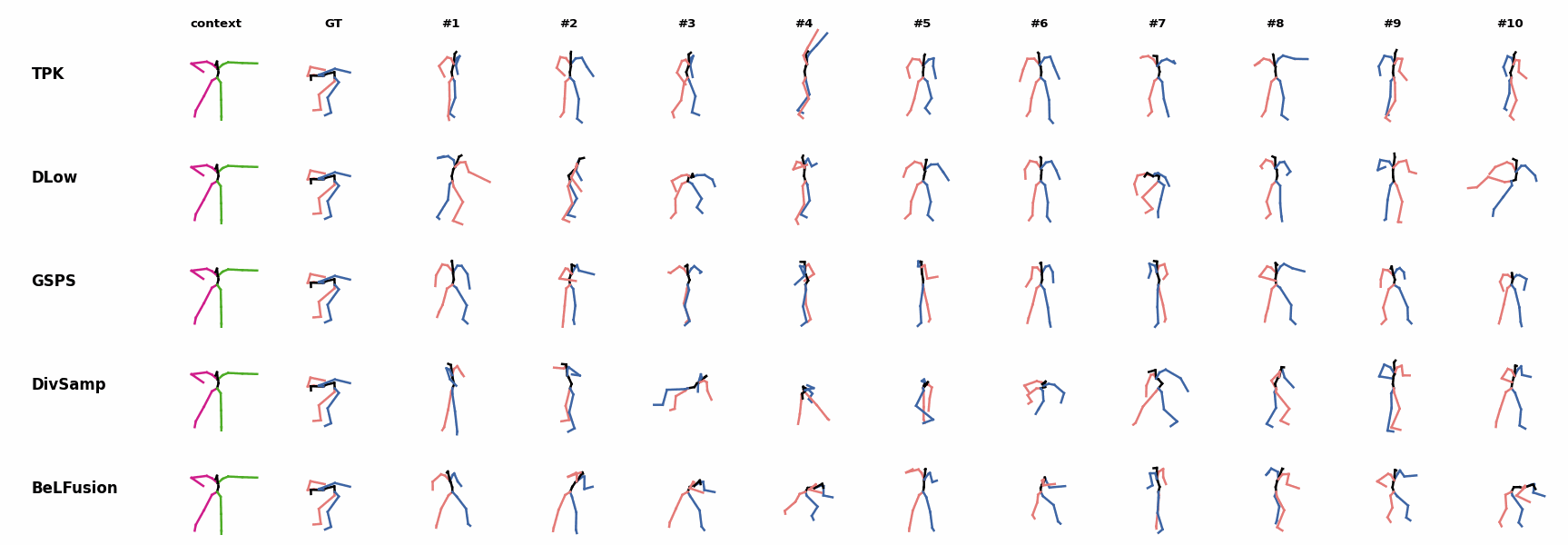 BeLFusion can predict, up to some extent, the correct continuation of a dance move, while other methods either almost freeze or simply predict an out-of-context movement.
BeLFusion can predict, up to some extent, the correct continuation of a dance move, while other methods either almost freeze or simply predict an out-of-context movement.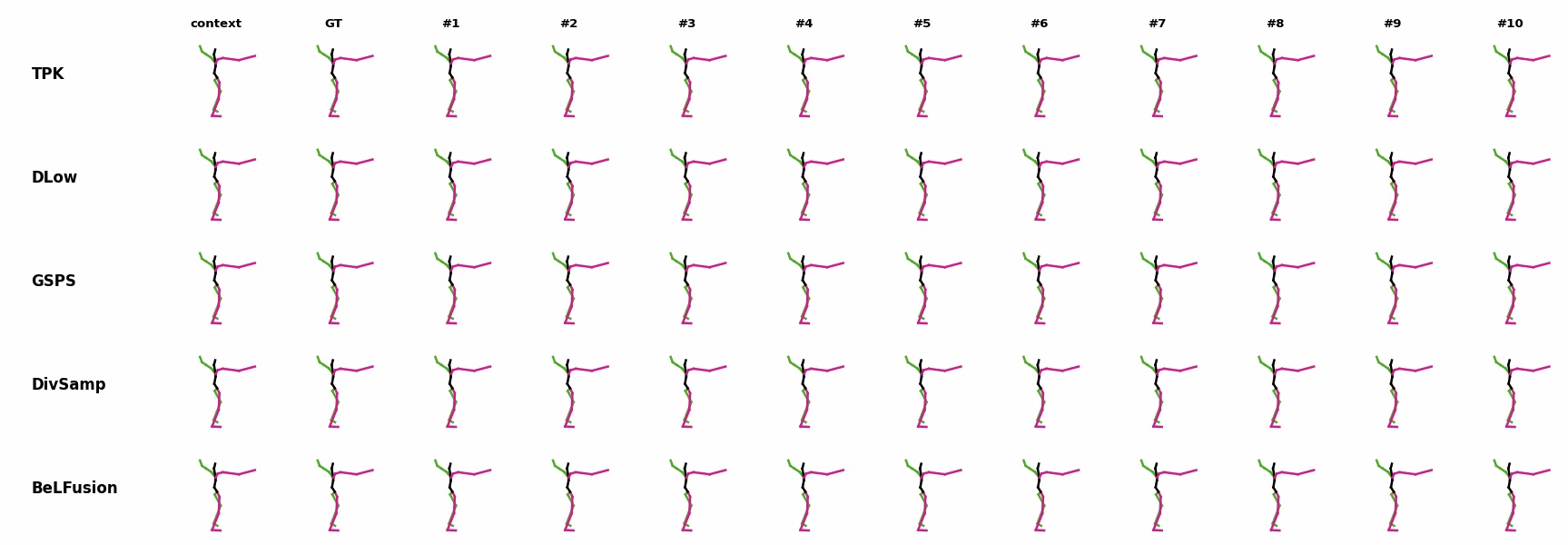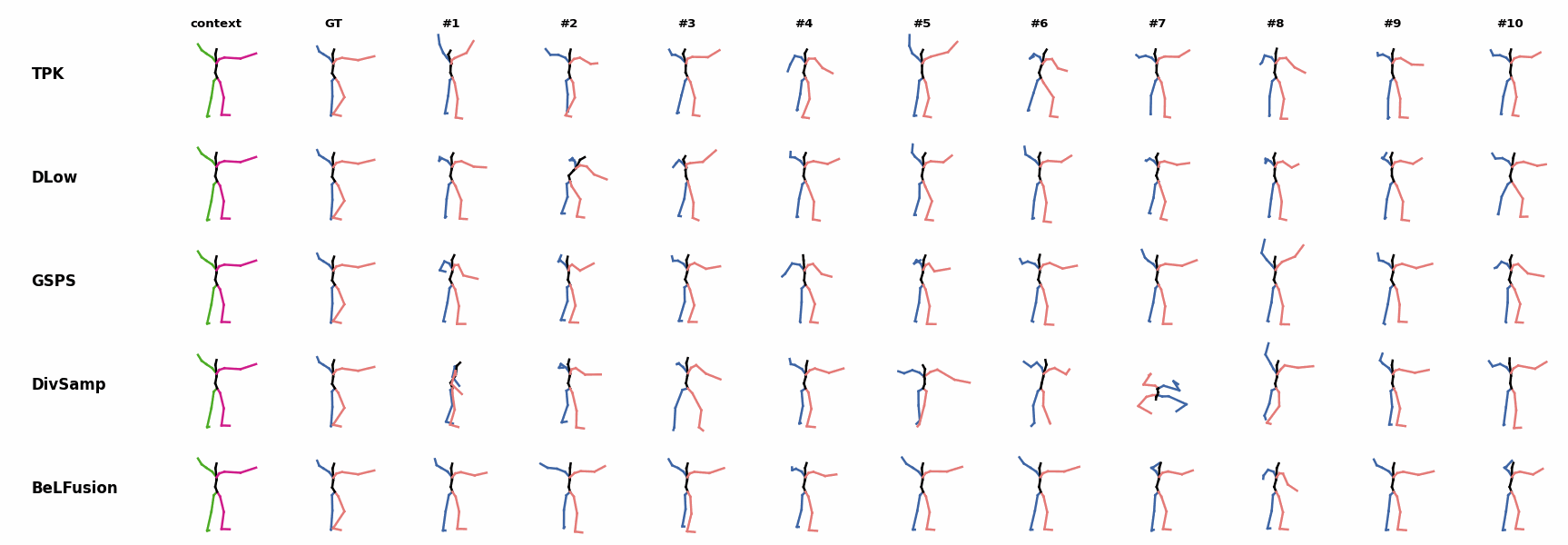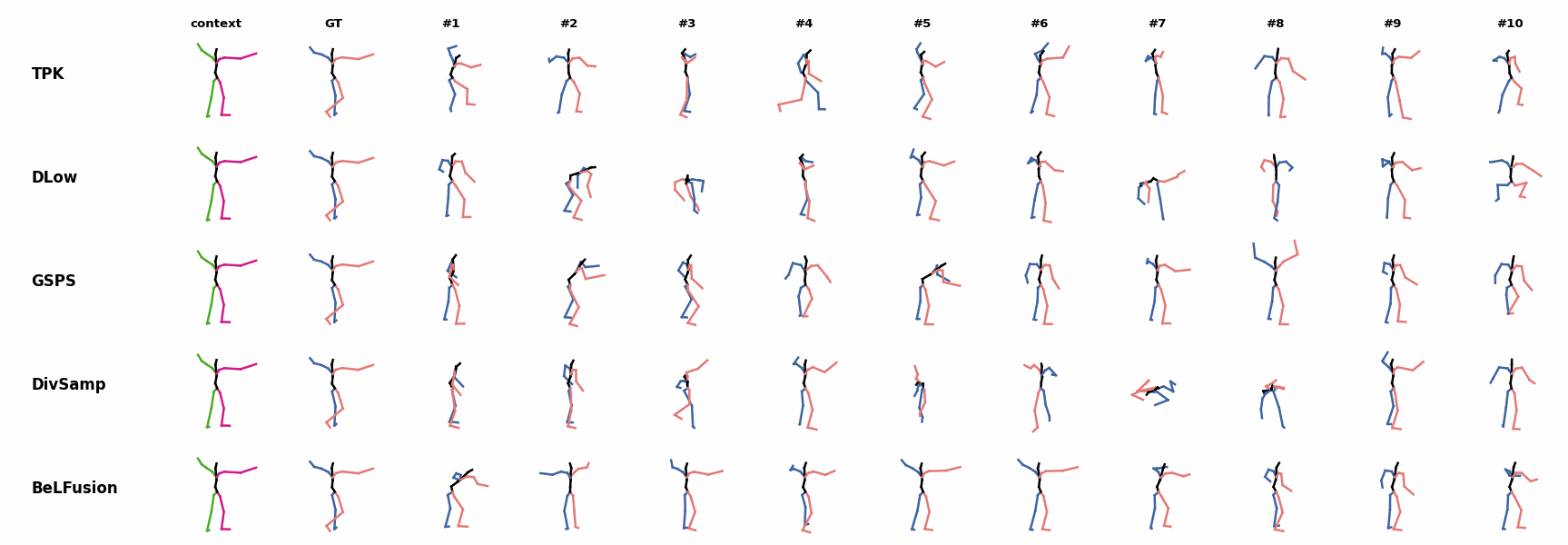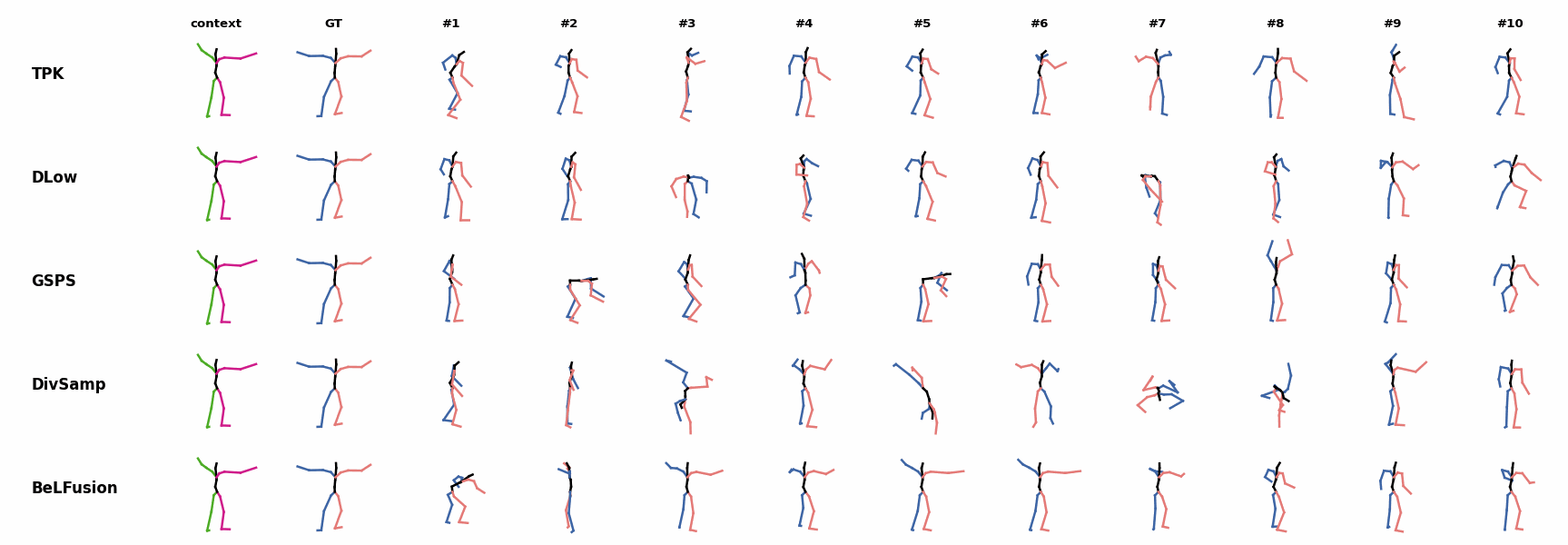 BeLFusion is able to detect that the dance moves involve keeping the arms arising while moving or rotating. In comparison, DLow, GSPS, and DivSamp simply predict other unrelated movements. TPK is only able to predict a few samples with fairly good continuations to the dance step.
BeLFusion is able to detect that the dance moves involve keeping the arms arising while moving or rotating. In comparison, DLow, GSPS, and DivSamp simply predict other unrelated movements. TPK is only able to predict a few samples with fairly good continuations to the dance step.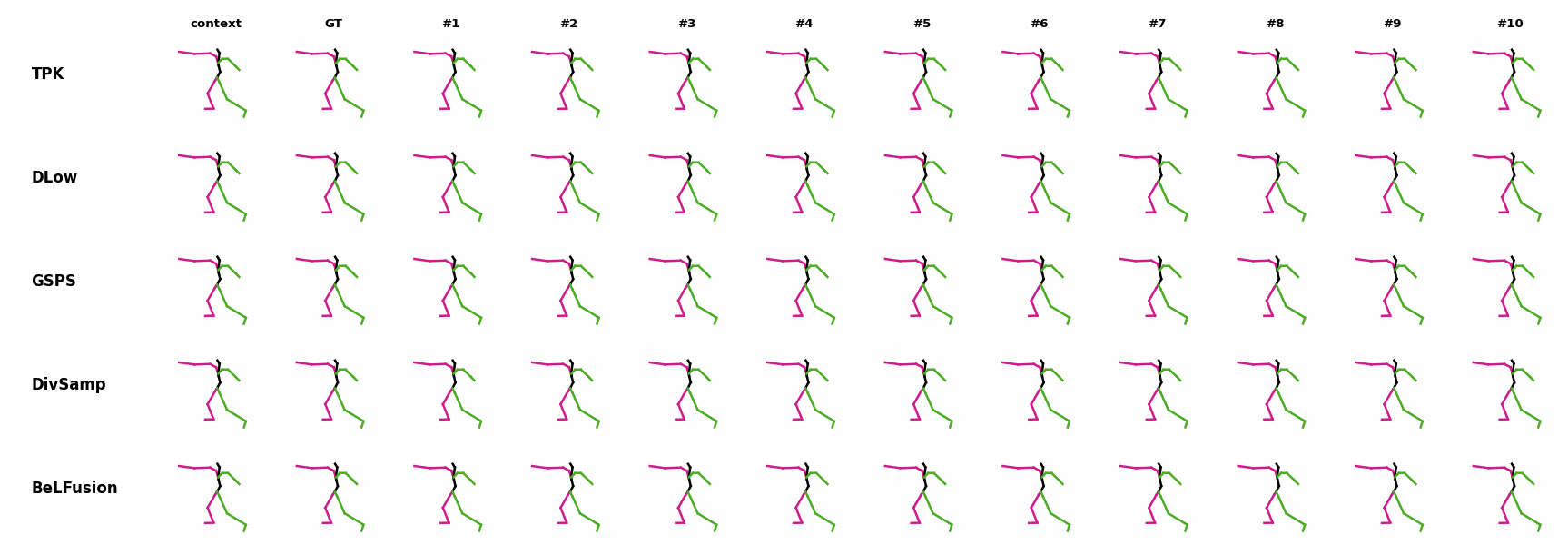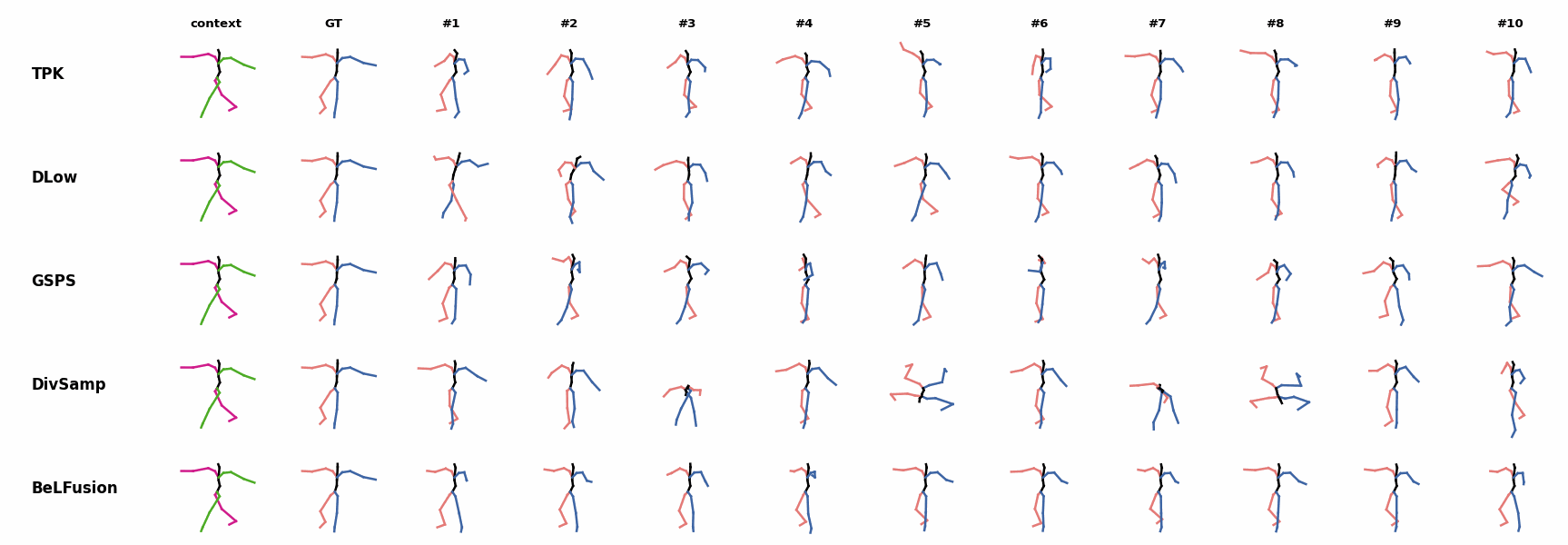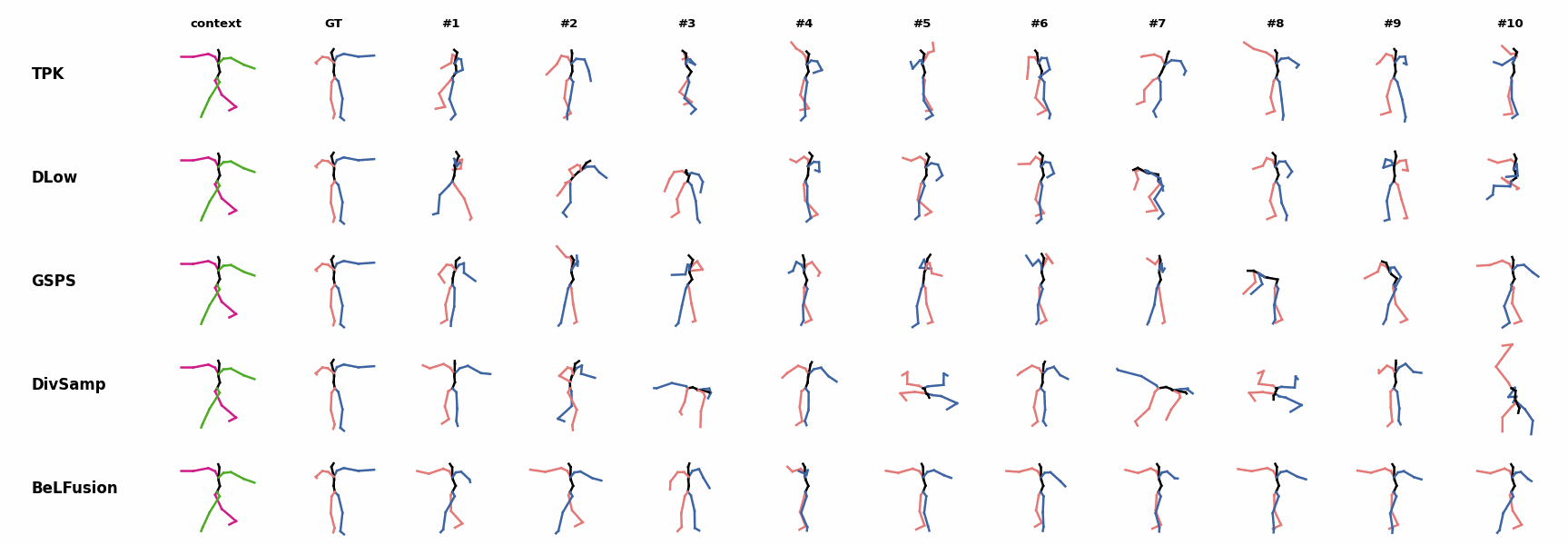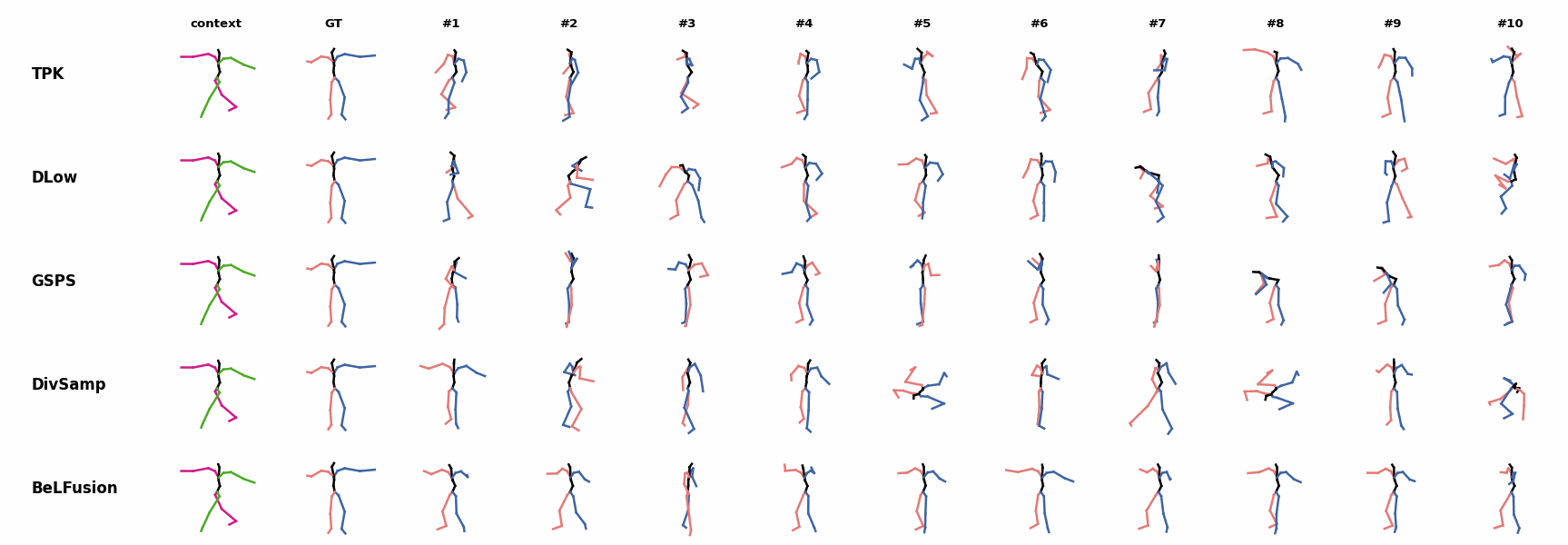 BeLFusion is the only method that generates predictions that slowly decrease its motion momentum to start performing a different action.
BeLFusion is the only method that generates predictions that slowly decrease its motion momentum to start performing a different action.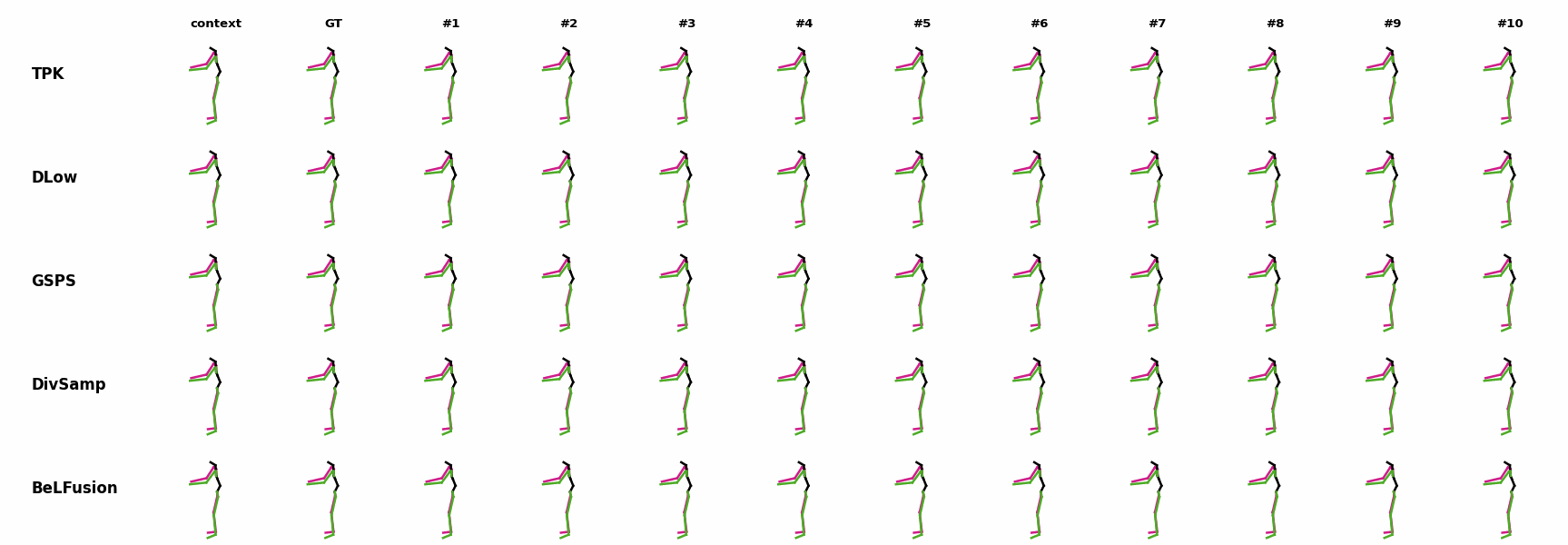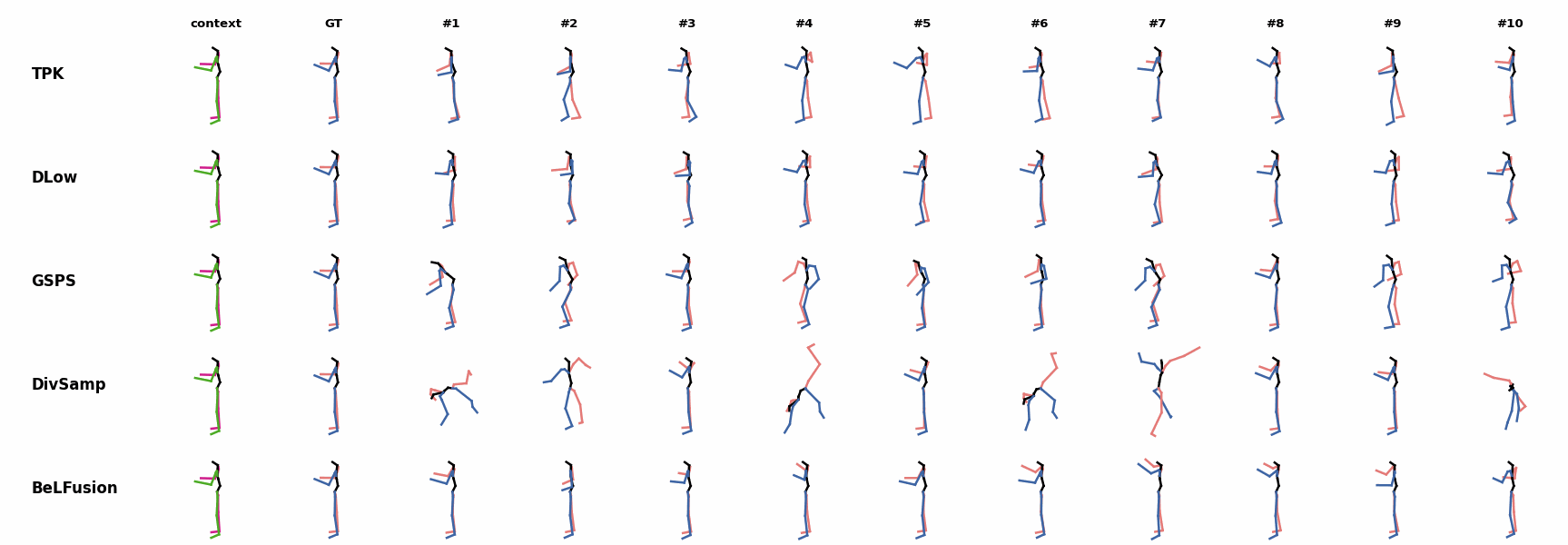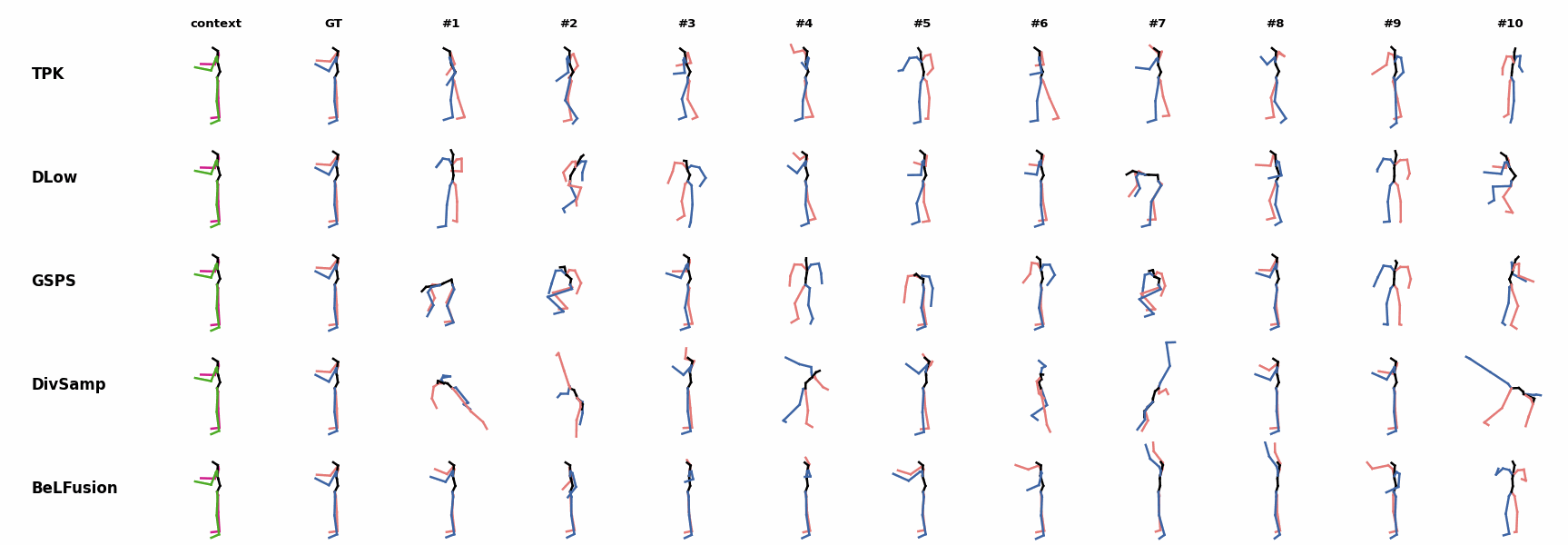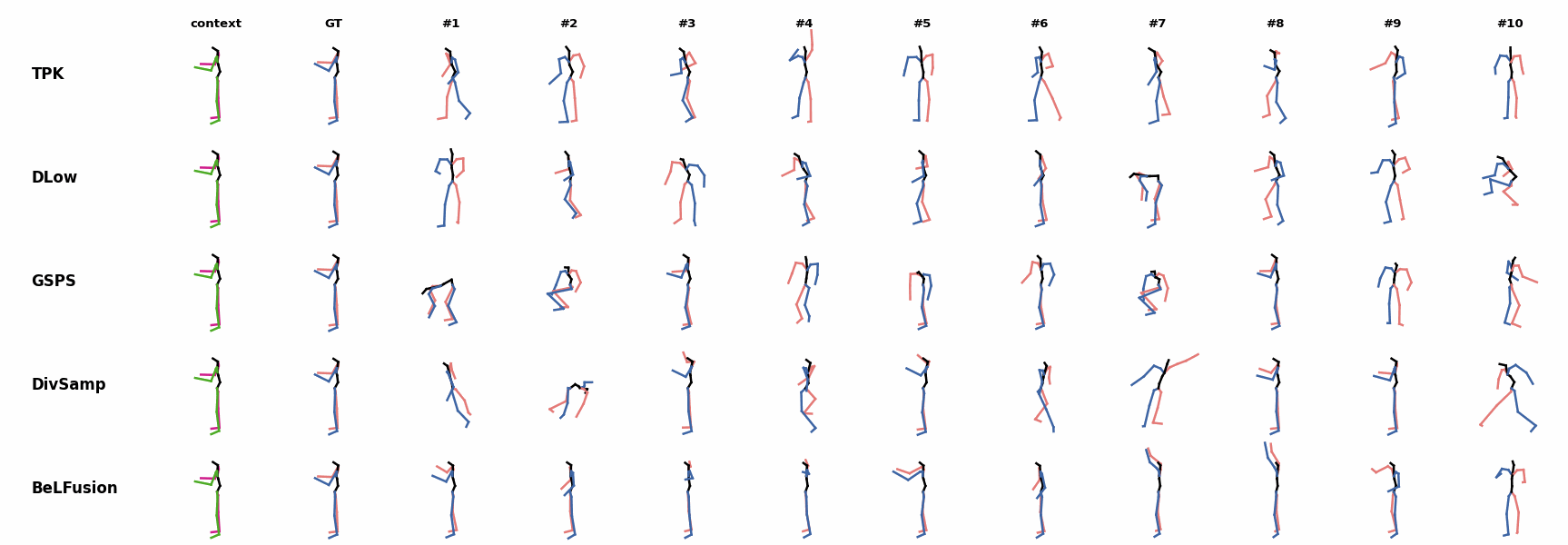 BeLFusion adapts the diversity of predictions to the ‘grabbing’ action present in the GRAB dataset. While other methods predict coordinate-wise diverse inaccurate predictions, our model encourages diversity within the short spectrum of the plausible behaviors that can follow.
BeLFusion adapts the diversity of predictions to the ‘grabbing’ action present in the GRAB dataset. While other methods predict coordinate-wise diverse inaccurate predictions, our model encourages diversity within the short spectrum of the plausible behaviors that can follow.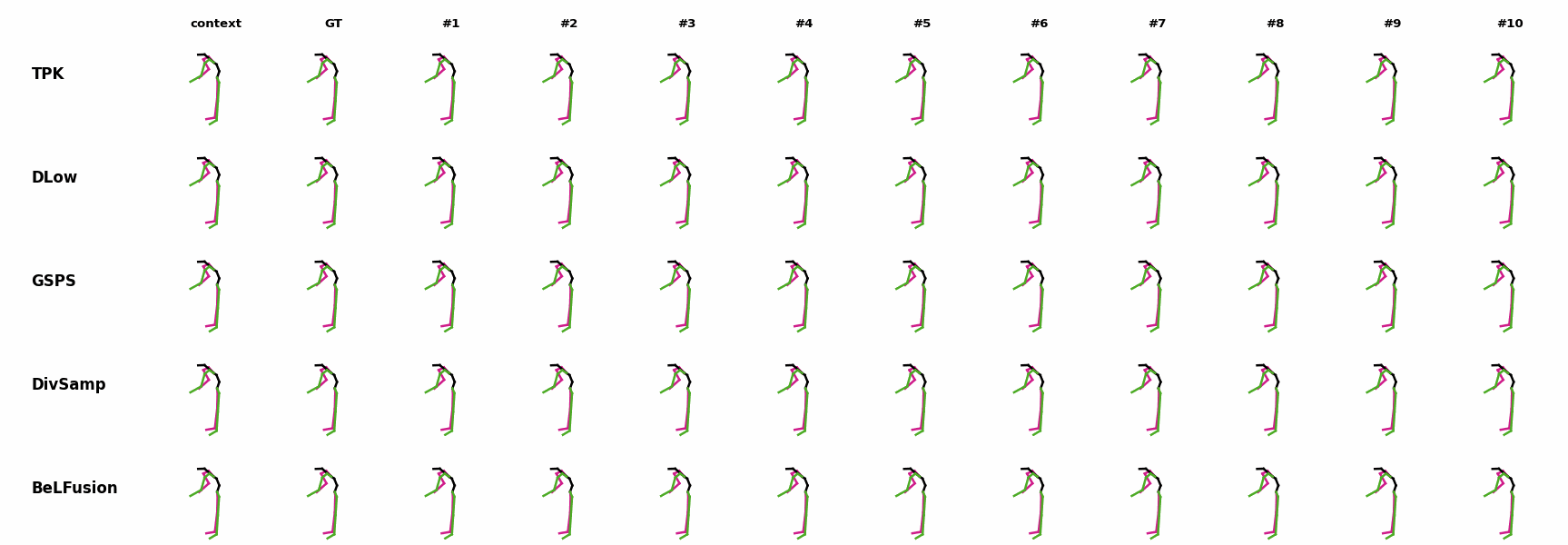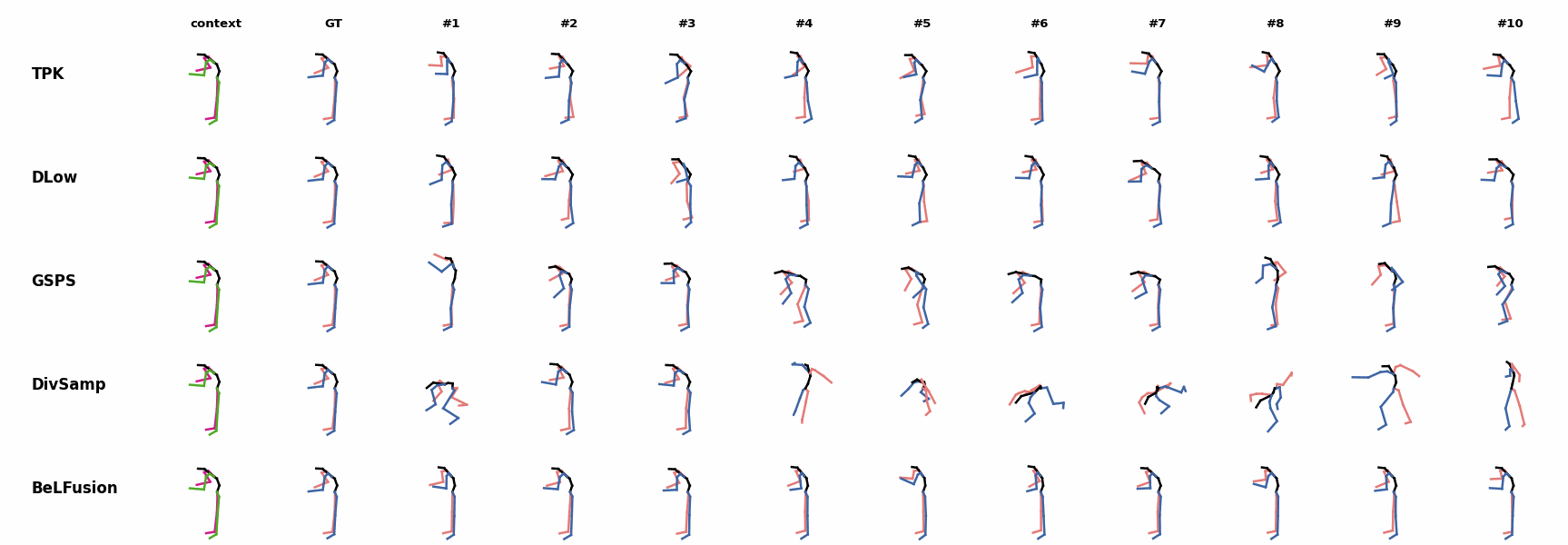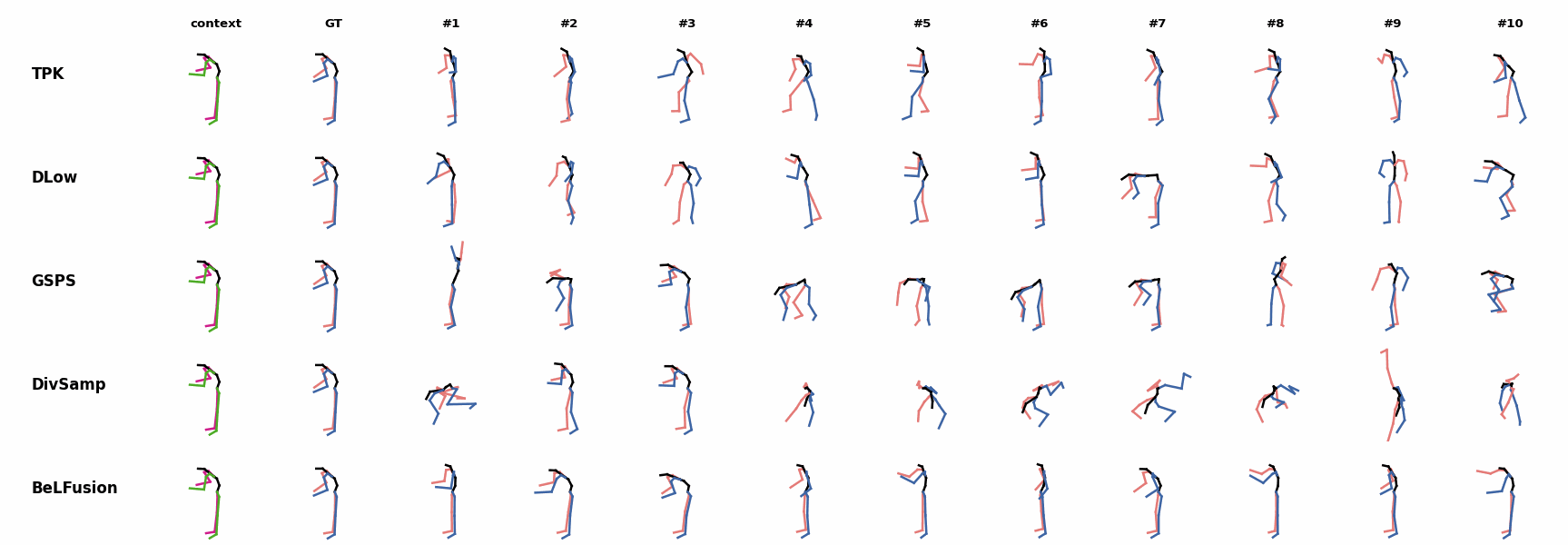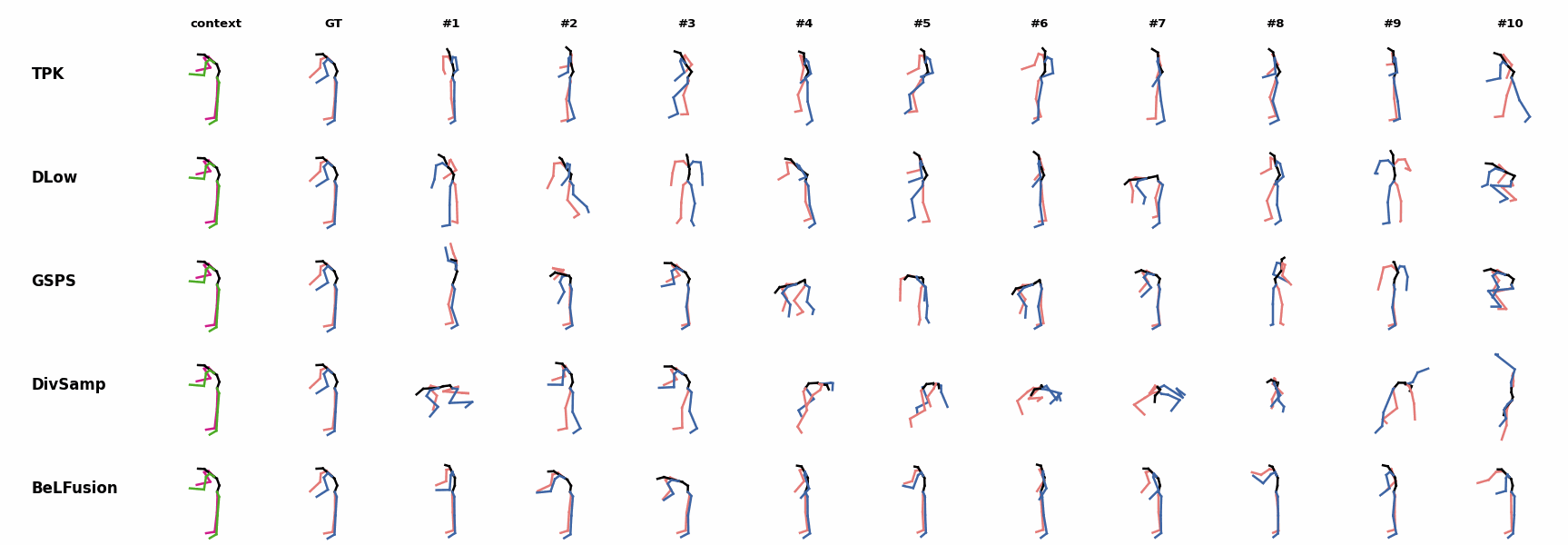 BeLFusion adapts the diversity of predictions to the ‘grabbing’ action present in the GRAB dataset. While other methods predict coordinate-wise diverse inaccurate predictions, our model encourages diversity within the short spectrum of the plausible behaviors that can follow.
BeLFusion adapts the diversity of predictions to the ‘grabbing’ action present in the GRAB dataset. While other methods predict coordinate-wise diverse inaccurate predictions, our model encourages diversity within the short spectrum of the plausible behaviors that can follow.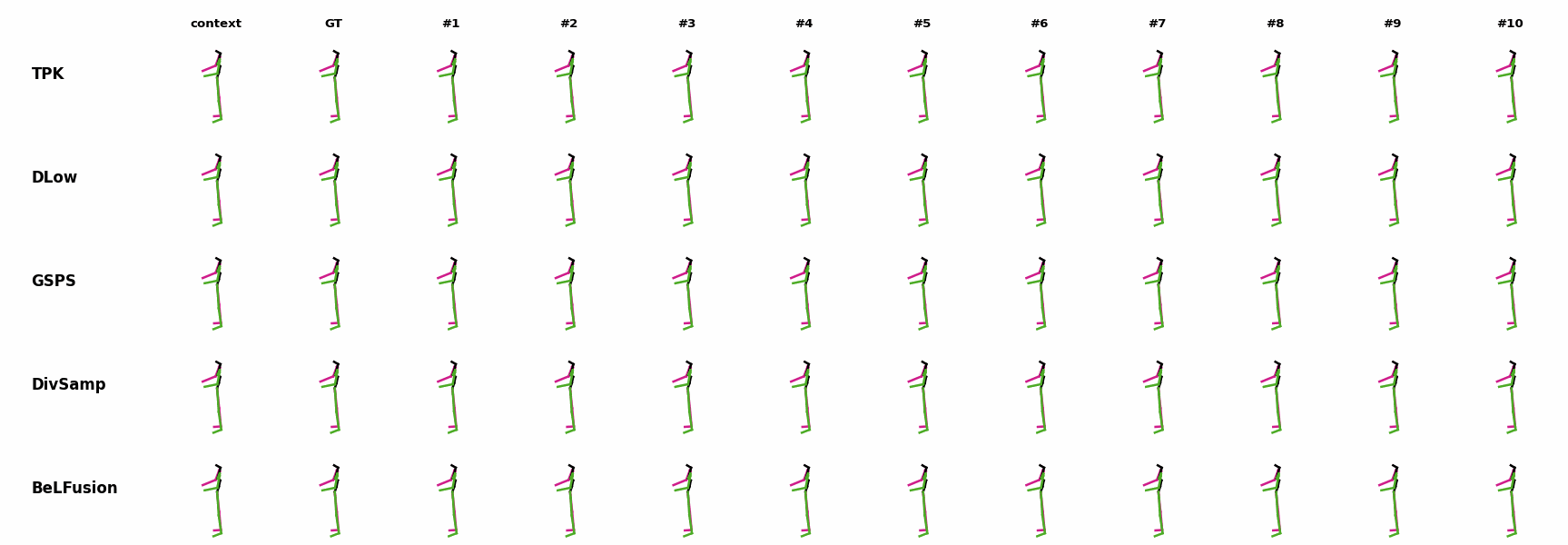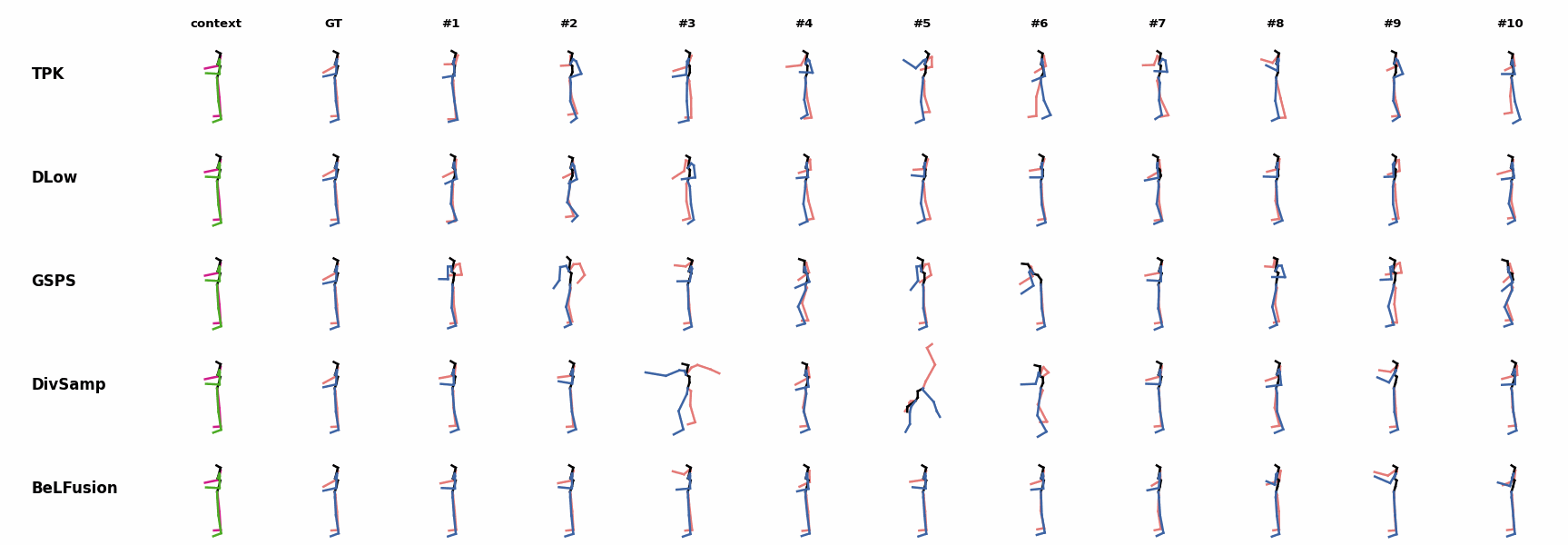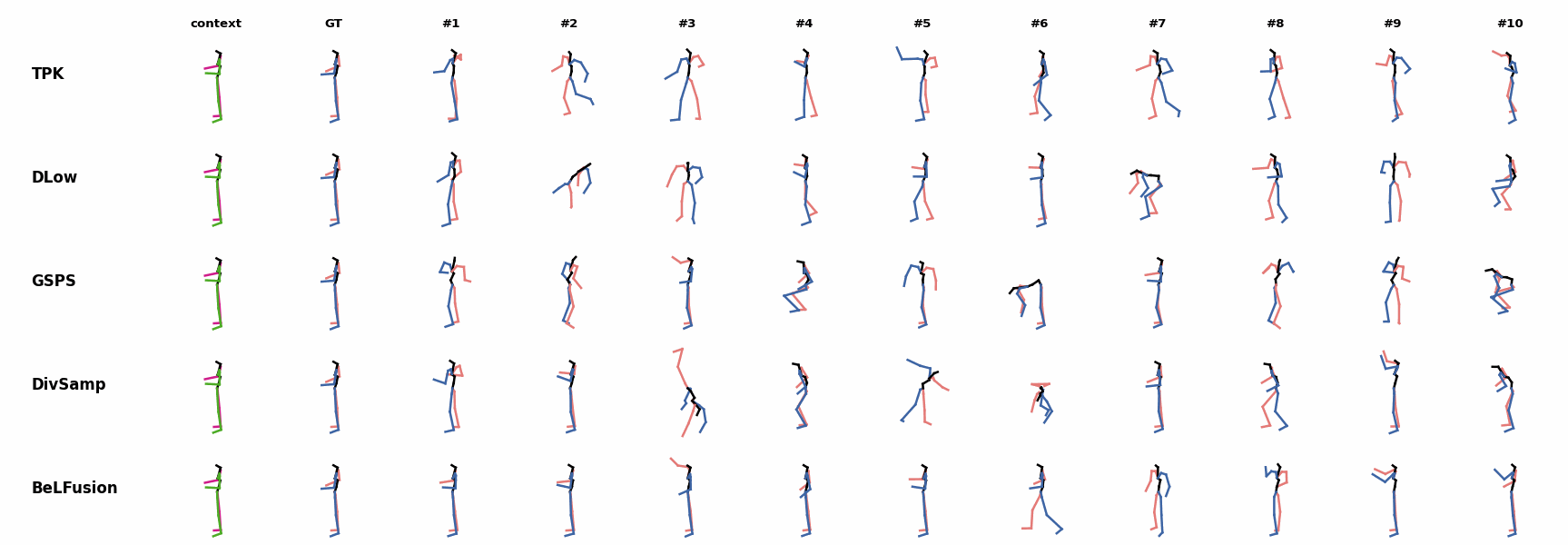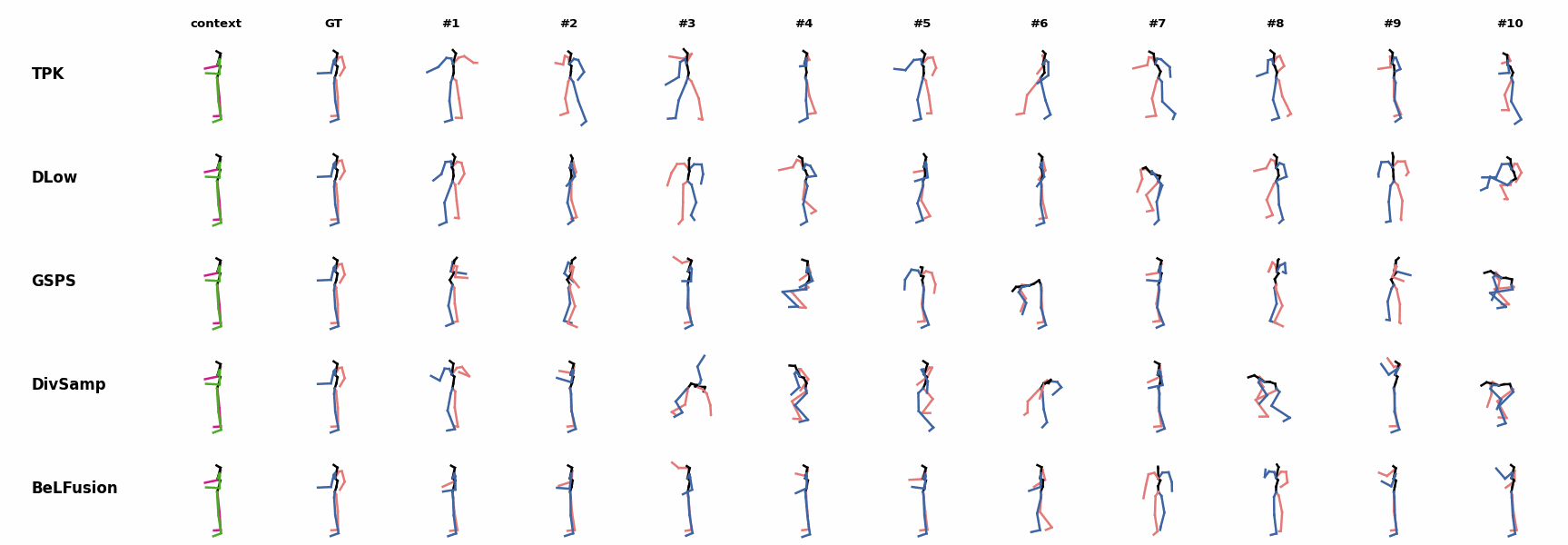 BeLFusion adapts the diversity of predictions to the ‘grabbing’ action present in the GRAB dataset. While other methods predict coordinate-wise diverse inaccurate predictions, our model encourages diversity within the short spectrum of the plausible behaviors that can follow.
BeLFusion adapts the diversity of predictions to the ‘grabbing’ action present in the GRAB dataset. While other methods predict coordinate-wise diverse inaccurate predictions, our model encourages diversity within the short spectrum of the plausible behaviors that can follow.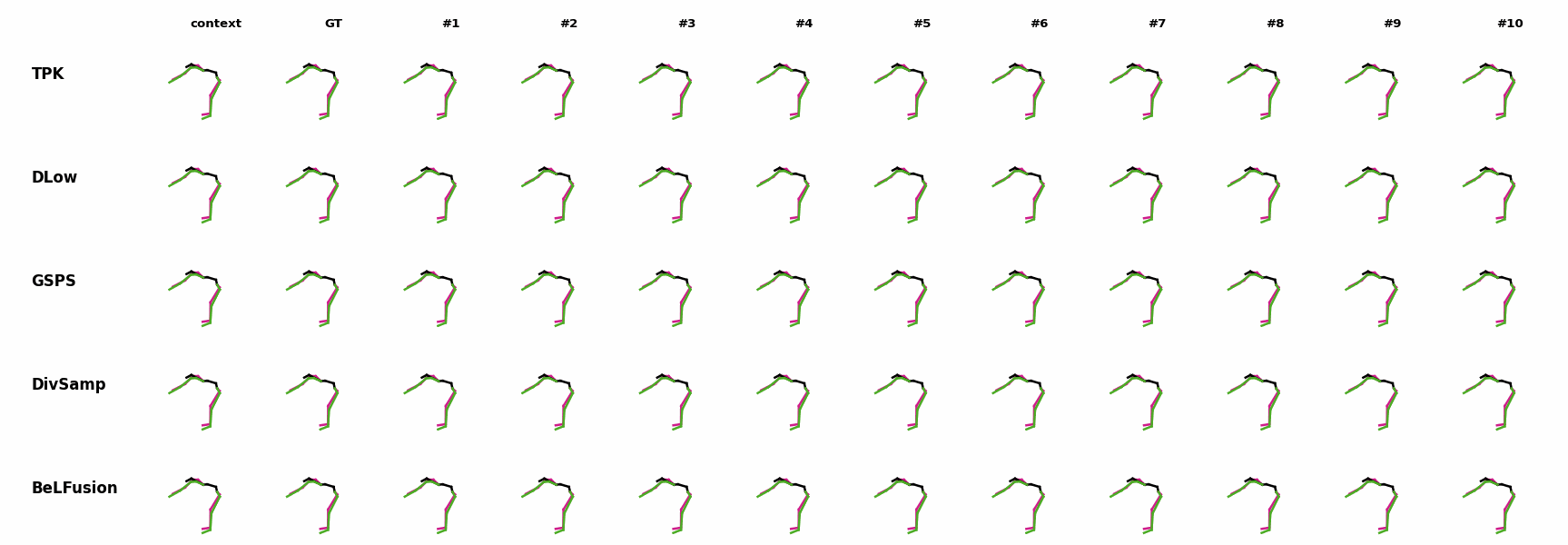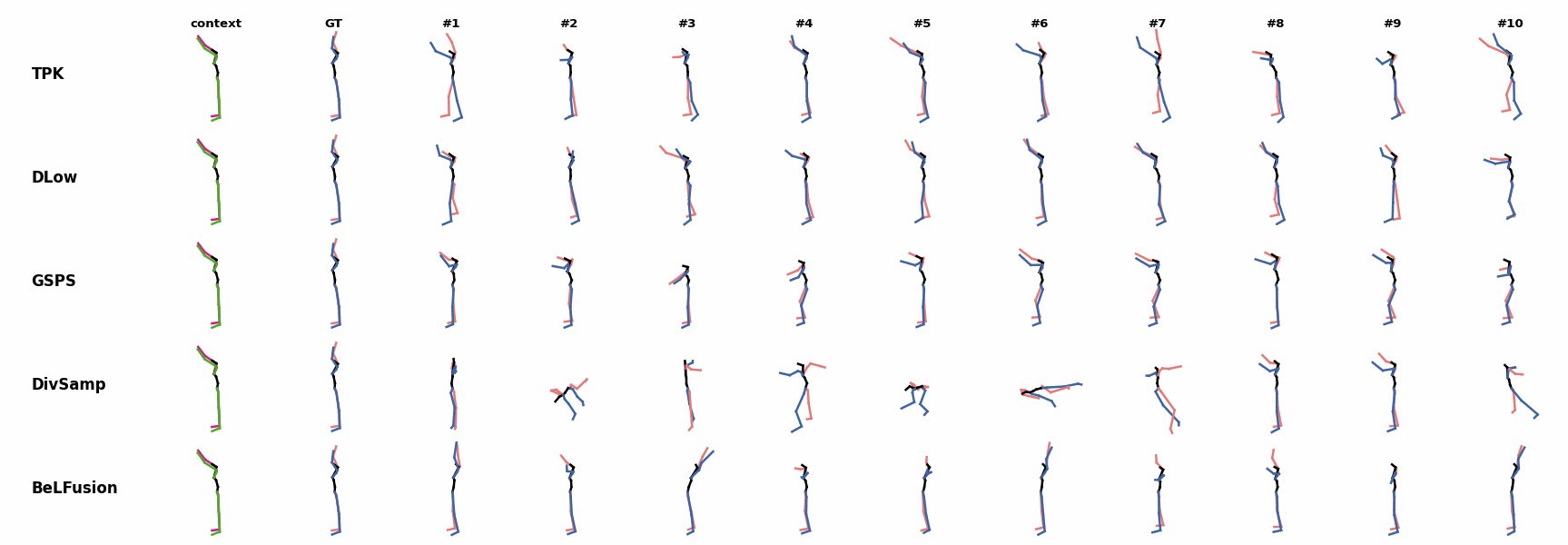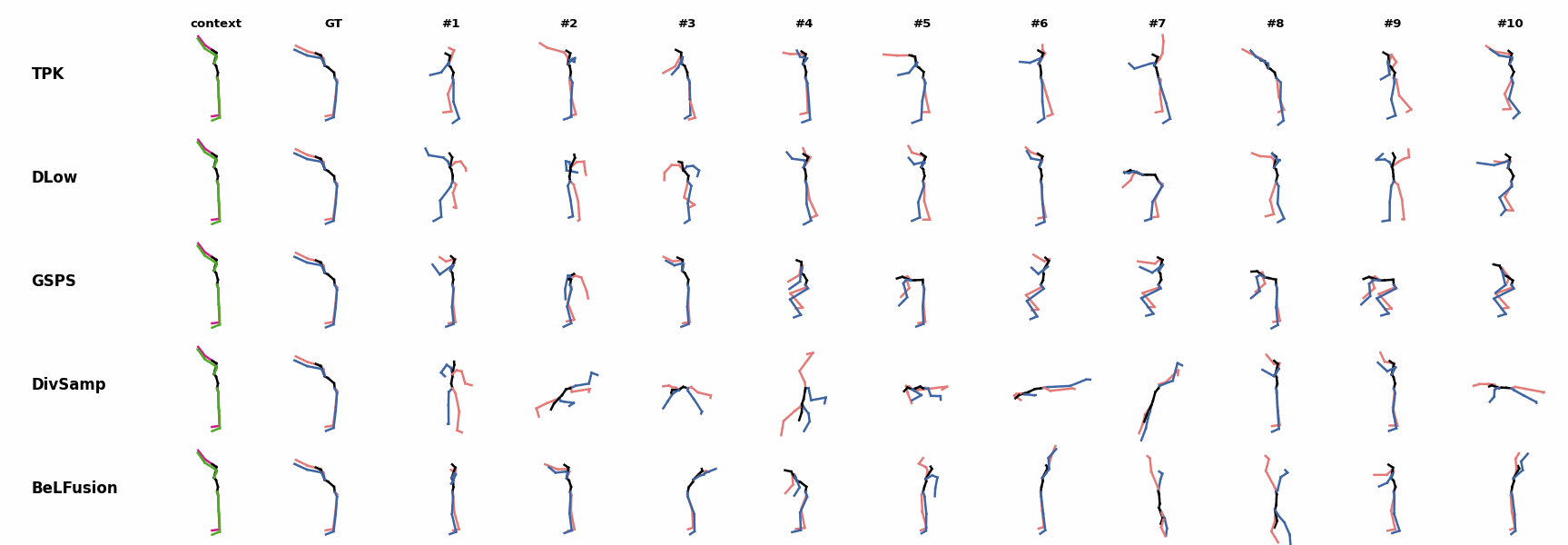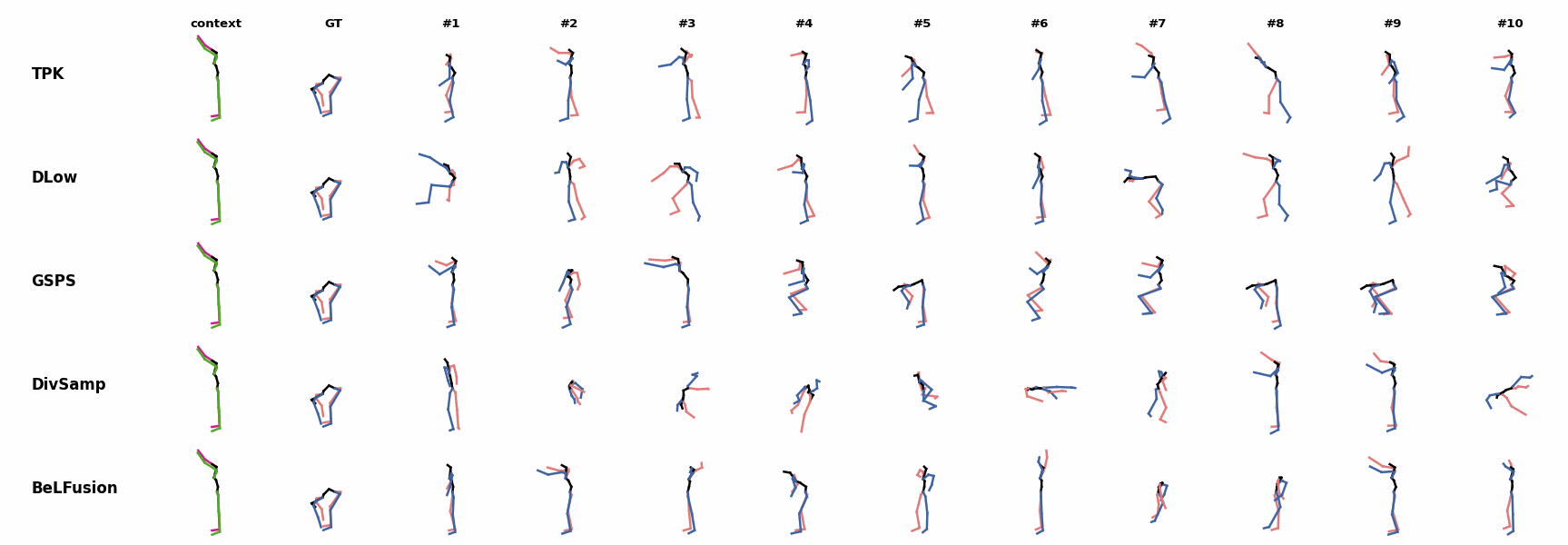 BeLFusion is the only method that generates predictions that slowly decrease its motion momentum to start performing a different action.
BeLFusion is the only method that generates predictions that slowly decrease its motion momentum to start performing a different action.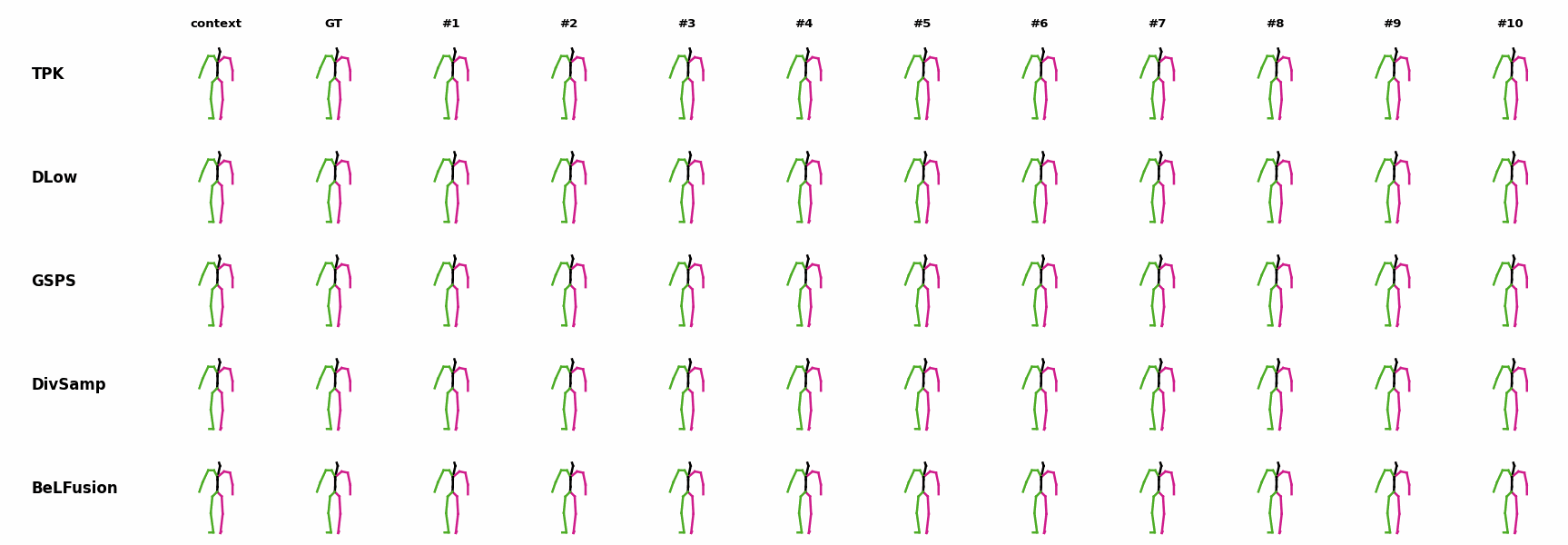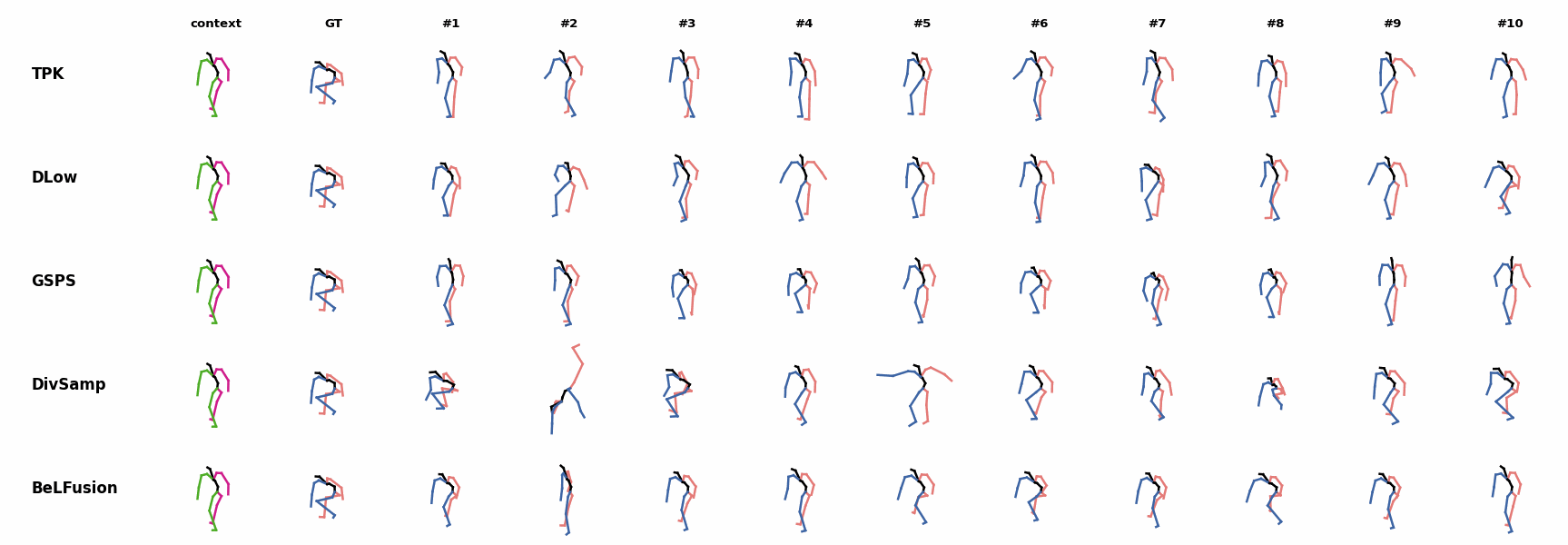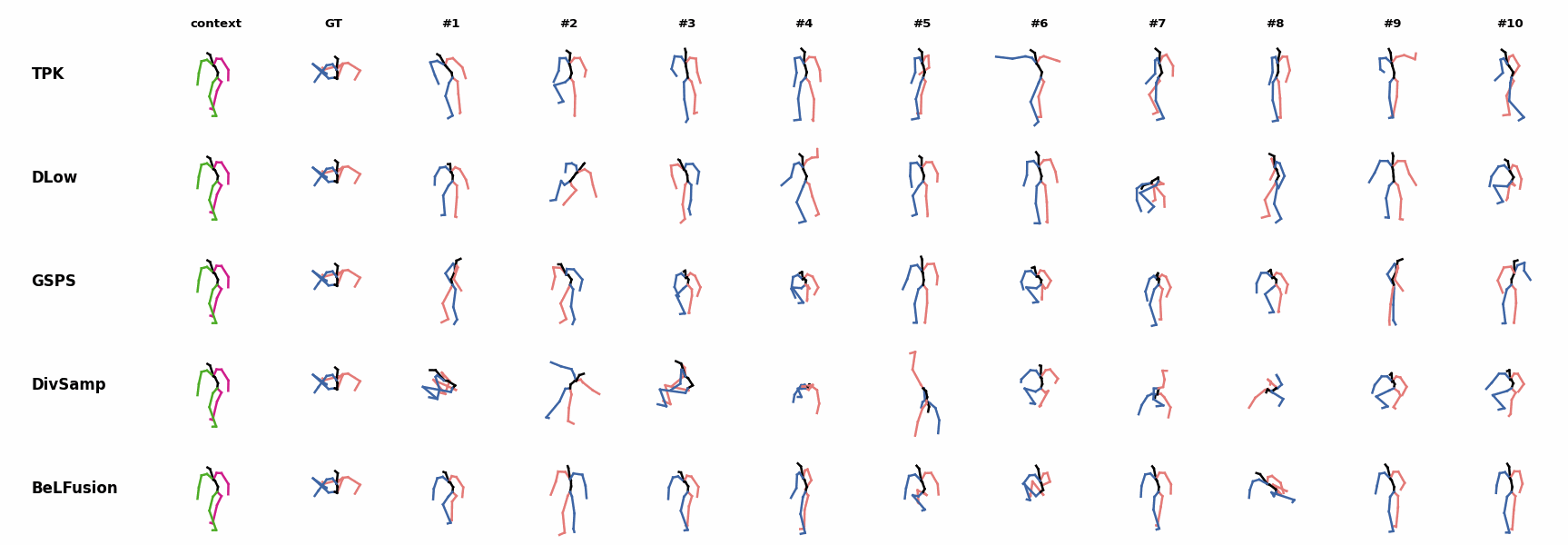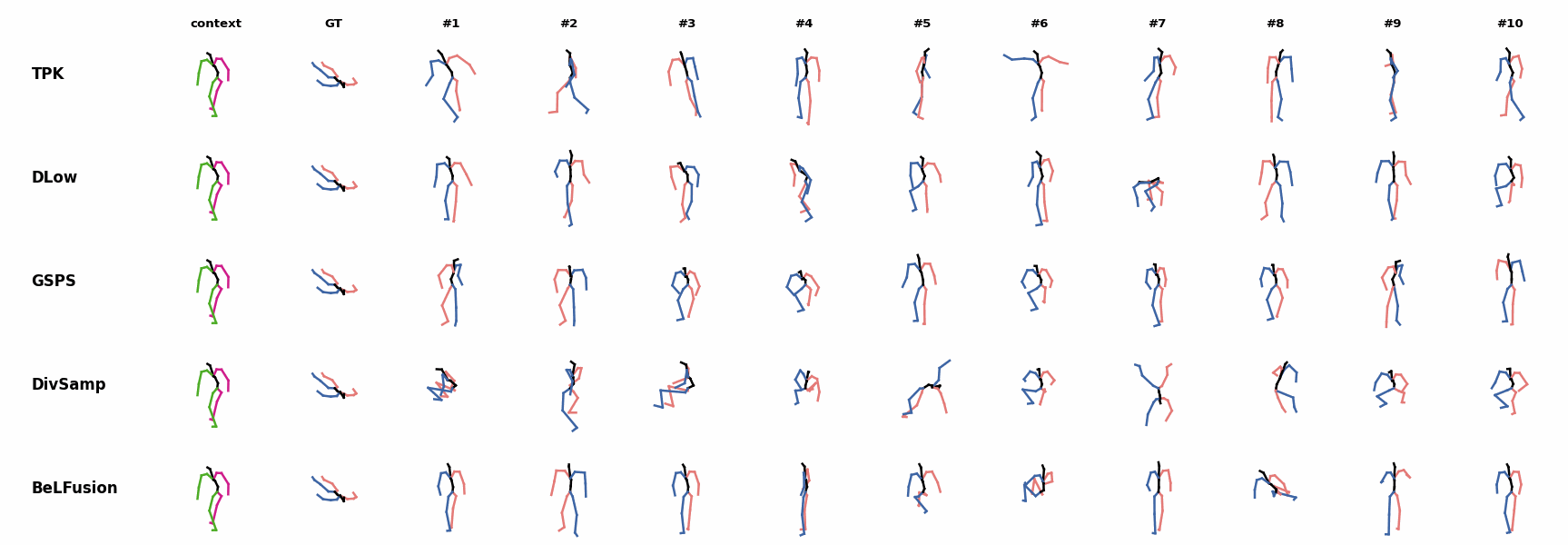 BeLFusion is the only able to anticipate the intention of laying down by detecting subtle cues inside the observation window (samples #6 and #8).
BeLFusion is the only able to anticipate the intention of laying down by detecting subtle cues inside the observation window (samples #6 and #8).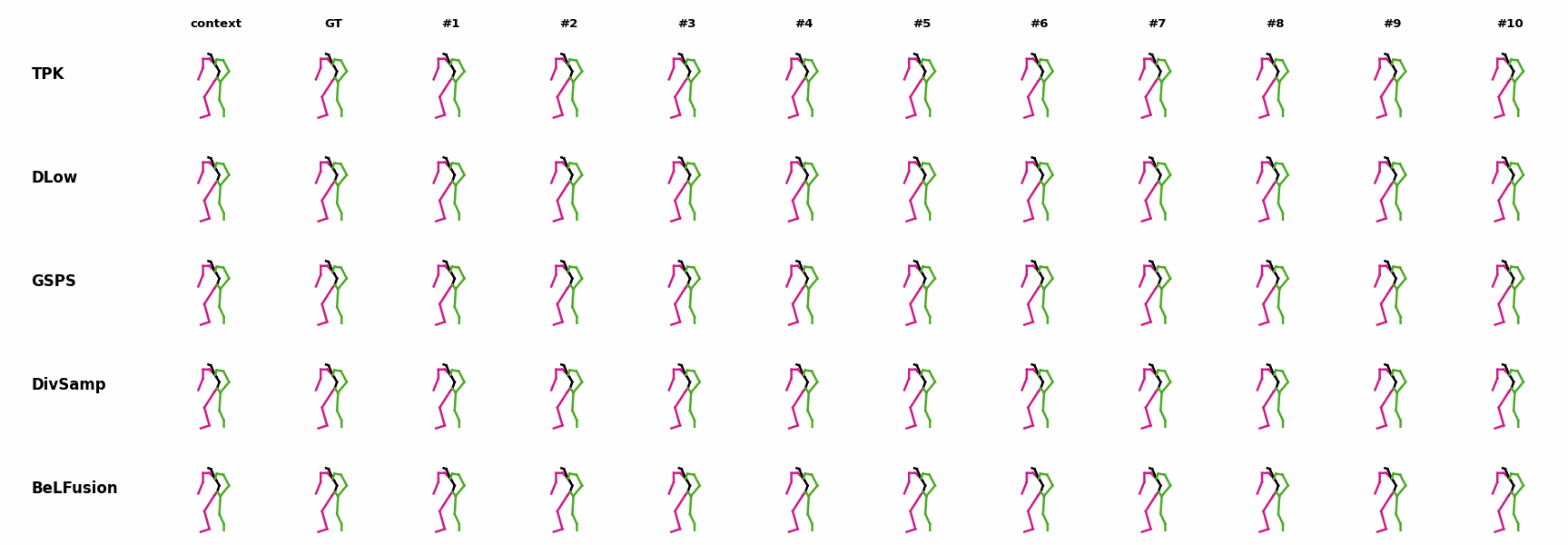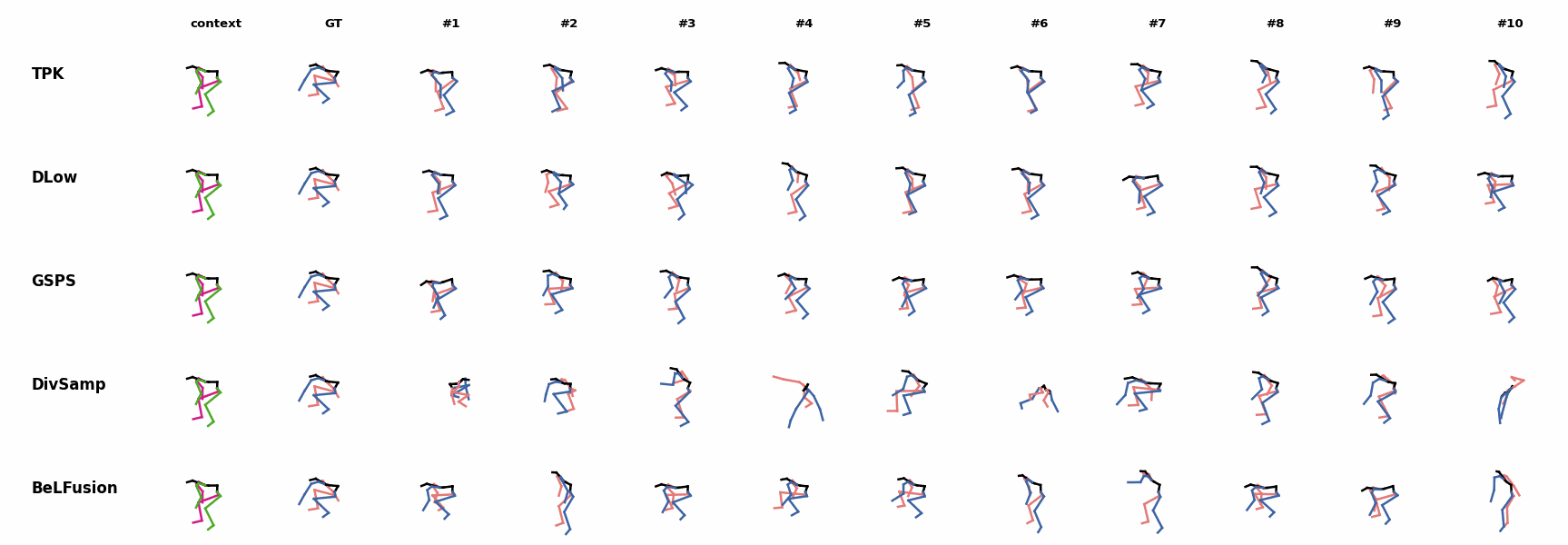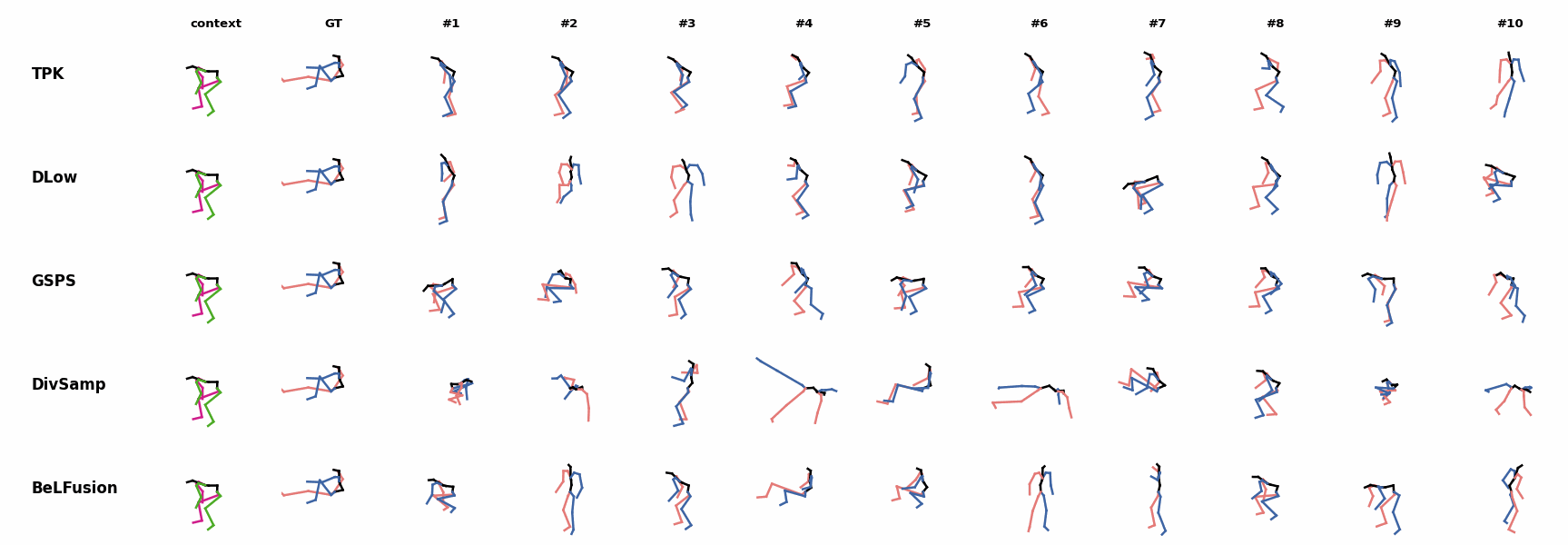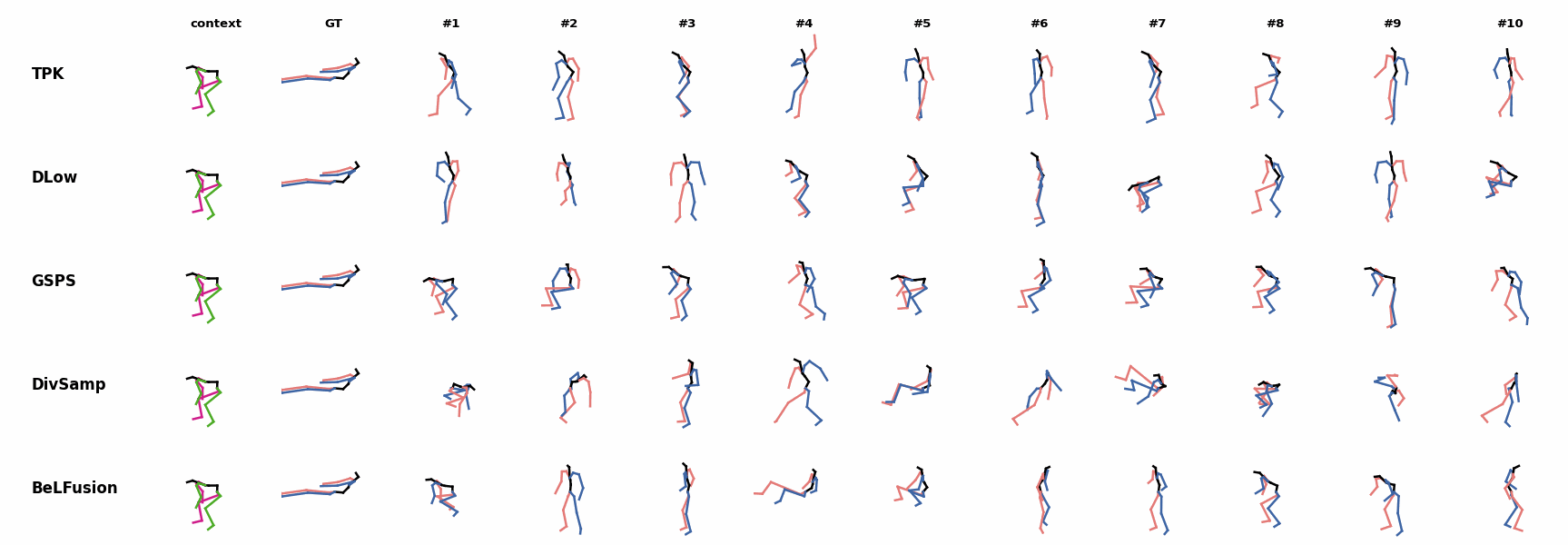 BeLFusion is the only able to anticipate the intention of laying down by detecting subtle cues inside the observation window (samples #6 and #8).
BeLFusion is the only able to anticipate the intention of laying down by detecting subtle cues inside the observation window (samples #6 and #8). BeLFusion is the only method able to infer how a very challenging repetitive stretching movement will follow.
BeLFusion is the only method able to infer how a very challenging repetitive stretching movement will follow.Others



The motion tagged as behavior shows the target behavior to be encoded and transferred. All the other columns show the ongoing motions where the behavior will be transferred to. They are shown with blue and orange skeletons. Once the behavior is transferred, the color of the skeletons switches to green and pink.
In ‘H1’ (H36M), the walking action or behavior is transferred to the target ongoing motions. For ongoing motions where the person is standing, they start walking towards the direction they are facing (#1, #2, #4, #5). Such transition is smooth and coherent with the observation. For example, the person making a phone call in #7 keeps the arm next to the ear while starting to walk. When sitting or bending down, the movement of the legs is either very little (#3 and #6), or very limited (#8). ‘H2’ and ‘H3’ show the transference of subtle and long-range behaviors, respectively.



The motion tagged as behavior shows the target behavior to be encoded and transferred. All the other columns show the ongoing motions where the behavior will be transferred to. They are shown with blue and orange skeletons. Once the behavior is transferred, the color of the skeletons switches to green and pink.
For AMASS (cross-dataset scenario), the behavioral encoding faces a huge domain drift. However, we still observe good results at this task. For example, ‘A1’ shows how a stretching movement is successfully transferred to very distinct ongoing motions by generating smooth and realistic transitions. Similarly, ‘A2’ and ‘A3’ are examples of transferring subtle and aggressive behaviors, respectively. Even though the dancing behavior in ‘A3’ was not seen at training time, it is transferred and adapted to the ongoing motion fairly realistically.
BibTeX
@inproceedings{barquero2023belfusion,
title={BeLFusion: Latent Diffusion for Behavior-Driven Human Motion Prediction},
author={Barquero, German and Escalera, Sergio and Palmero, Cristina},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
year={2023}
}